I have a neurons-to-ensemble connection of which I would like to modulate the weights at runtime to implement a custom learning algorithm.
Is this possible without having to define a new learning_rule? I was trying something like this, with a Node modifying the decoders vector entries at each timestep, but the probes I set up seems to indicate that the connection is not being modulated.
Is it the case that self.decoder in:
self.conn = nengo.Connection( pre.neurons, post, transform=self.decoder )
is passed at build time and then is immutable unless using a learning_rule?
The following statement does not seem to alter the connection:
self.decoder in this case is specifying the initial value for the connection weights, not the live simulation value. When you instantiate a Simulator, all those initial parameter values in your Network definition are read into the Simulator, but then after that the initial value isn’t read again so modifying it won’t have any effect.
You can achieve what you want with a Node, but it’s pretty hacky (since you’re essentially trying to hack internal simulation logic into a Node). Here’s an example
import nengo
with nengo.Network() as net:
a = nengo.Ensemble(10, 1)
b = nengo.Node(size_in=1)
# we need to add a learning rule here, even though we won't be using it,
# in order to mark the weights as modifiable. so we'll just use a PES
# rule with a learning rate of 0
conn = nengo.Connection(a, b, learning_rule_type=nengo.PES(0))
p = nengo.Probe(b)
# this is the Node function that will be implementing the learning rule.
# we have to use a callable class, because we need to store the internal
# simulator state
class MyNodeLearningRule:
def __init__(self):
# these will be references to the internal simulator state, which
# doesn't exist when the Node is first created. so we initialize
# with empty values, which we will fill in after the Simulator
# is instantiated
self.weight_sig = None
self.signals = None
def __call__(self, t):
# this is where you'd implement your learning rule logic, here
# we'll just set the weights to 0 as an example
self.signals[self.weight_sig][...] = 0
# make sure to specify size_out, otherwise Nengo will try to call the node
# function to determine size_out, which isn't possible at this point
# because we haven't filled in the Simulator state variables
learning_node = nengo.Node(MyNodeLearningRule(), size_out=0)
with nengo.Simulator(net) as sim:
# now that the Simulator has been created, we can fill in
# the required values in the Node function
learning_node.output.signals = sim.signals
learning_node.output.weight_sig = sim.model.sig[conn]["weights"]
sim.run_steps(10)
print(sim.data[p])
As you can see, it’s definitely awkward. If possible I’d recommend implementing a custom Learning Rule instead, as that’s designed to allow you to write code that modifies the Simulator state in a much more structured way.
Ok, thanks! I was imagining as such.
I think I’ll try to implement a working neuron to neuron connection first by calculating a weight matrix at runtime in the Node(), as that seems to work.
I was reading in some older topics (~2016) about a GenericRule() object and have found references to it on the official GitHub. It was indicated that the implementation would be moved to the nengo-extras repo but, alas, I can’t seem to find it. Has it been scrapped? In that case, would it be too much to ask, even at a high-ish level for now, how to implement a custom rule?
No, unfortunately that generic learning rule never got merged in.
As for writing your own learning rule, we don’t have an exact example of that. However, we have this example of defining a custom neuron type, and the process is essentially the same (except you’re adding a new learning rule class instead of a new neuron type).
The first thing you need to do is implement a subclass of LearningRuleType that stores all the parameters for your learning rule. You can see an example of what the PES class looks like here https://github.com/nengo/nengo/blob/master/nengo/learning_rules.py#L104. This class doesn’t really do much, basically you just have a constructor that takes in the arguments you want and then stores them.
Then you need to write the simulator operator that implements your learning rule. You can see an example of the PES operator here https://github.com/nengo/nengo/blob/master/nengo/builder/learning_rules.py#L12. The constructor should take in arguments which are the Signals your learning rule reads and writes to. All learning rules take in the delta signal, which is the signal you will be writing to (representing the change to be applied to the connection weights). Any other signals required (e.g. an error signal, or the presynaptic activities), will depend on the implementation of your learning rule.
The main functionality of your learning rule is in the make_step function of that operator class. This is where you read the values of any input signals, and return a function that implements the learning rule update (e.g. the step_simpes function here https://github.com/nengo/nengo/blob/master/nengo/builder/learning_rules.py#L110). Note that the signals argument in make_step is the same signals Simulator object we were accessing in the Node implementation above.
Finally, you need to write a build function for your new learning type. You can see an example of the PES build function here https://github.com/nengo/nengo/blob/master/nengo/builder/learning_rules.py#L687. This is the function that tells Nengo what to do when it’s building a model with the new learning type you created. Mainly what this function is doing is creating all the input/output Signals required by your learning rule, and then adding the operator you created in the previous step.
Let us know if you run into any issues and we can provide more detailed advice!
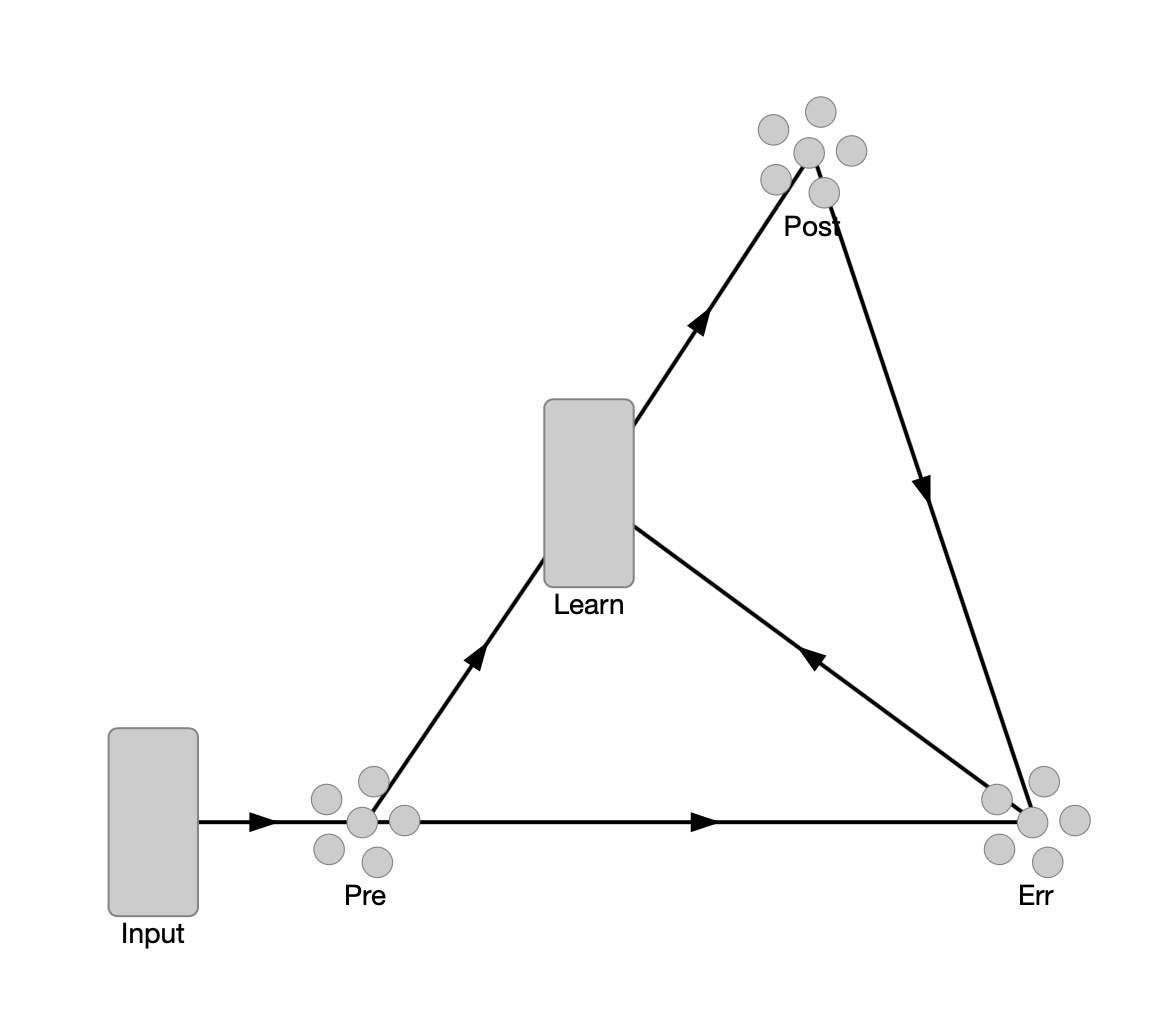
I was just wondering if I could ask for some help in debugging some related code I am writing, because I think I am doing everything right in modulating the weights between pre and post ensembles (similarly to here) but the output of post still does not seem to change. Some extra context of what I’m trying to achieve can be found here, but, to recap, I’m essentially trying to implement network weights using a memristor model.
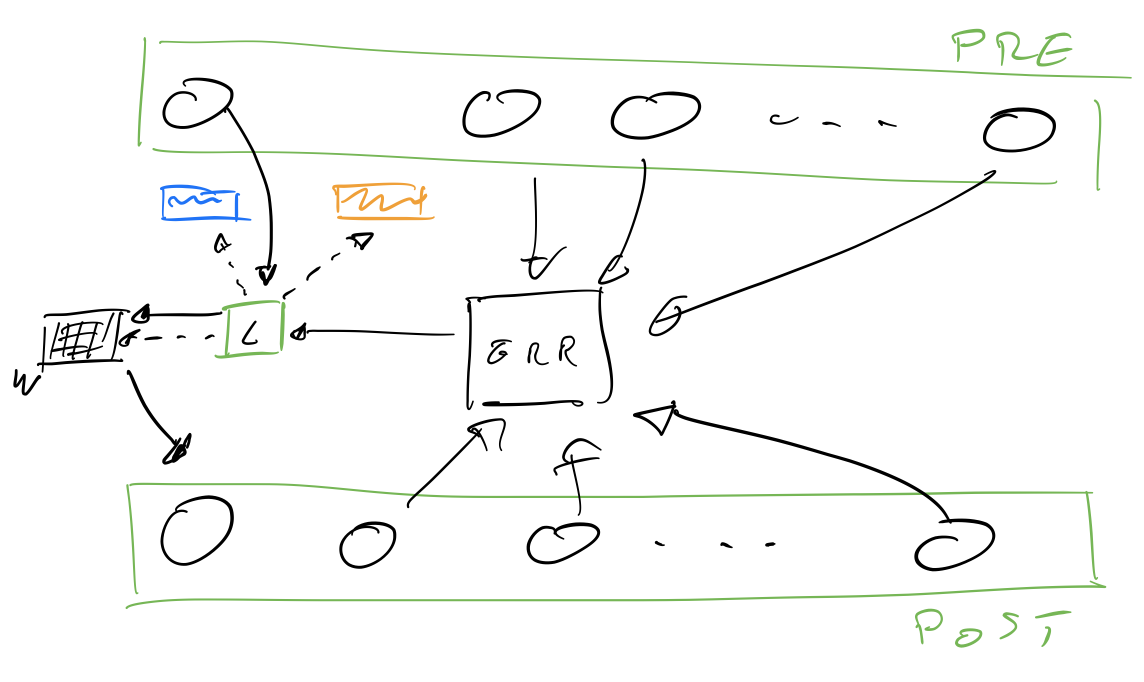
My full code can be found here, but I’ll try and point out some highlights:
I’m working with the simplest supervised learning setup, Learn is a nengo.Node() where I implement my weights and learning rule:
The first thing that the Learn node does is initialise an array of Memristors of size (post.n_neurons,pre.n_neurons) (here)
self.memristors = np.empty( (self.output_size, self.input_size), dtype=Memristor )
for i in range( self.output_size ):
for j in range( self.input_size ):
if self.type == "single":
self.memristors[ i, j ] = Memristor( self.input_size, self.output_size, "excitatory", r0, r1, a, b )
if self.type == "pair":
self.memristors[ i, j ] = MemristorPair( self.input_size, self.output_size, r0, r1, a, b )
Then at each timestep dt it checks which neurons in pre have fired and applies the learning rule to the memristors representing its weights (here)
spiked = True if input_activities[ j ] else False
if spiked:
# update memristor resistance state
self.memristors[ i, j ].pulse( error )
Finally, it constructs a new weight matrix and convolves it with the input activations to give the connection’s outputs (here)
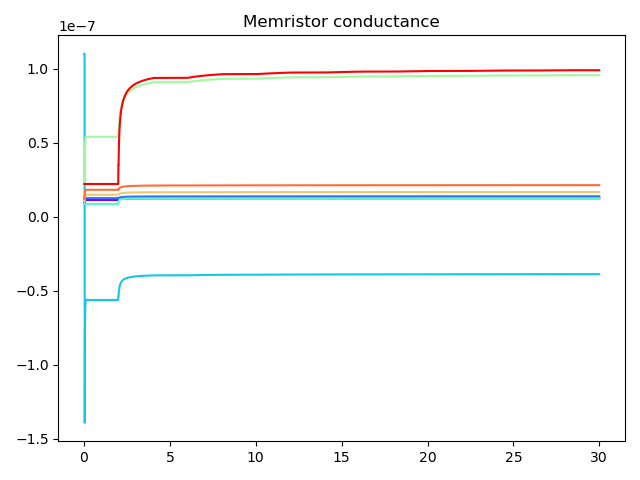
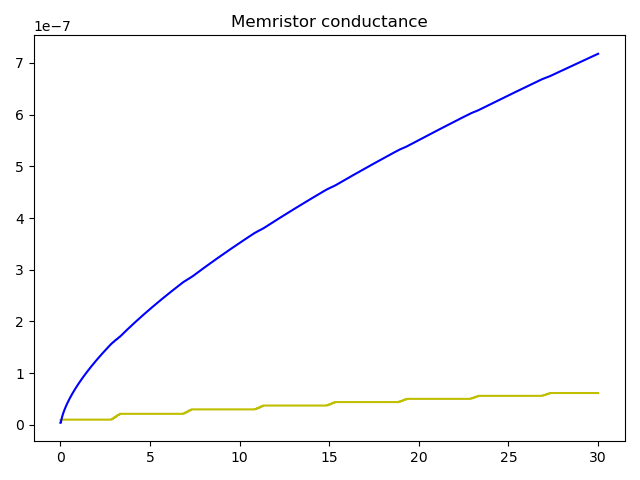
I know that my weights are being modulated because I keep track of them internally and can plot them at the end:
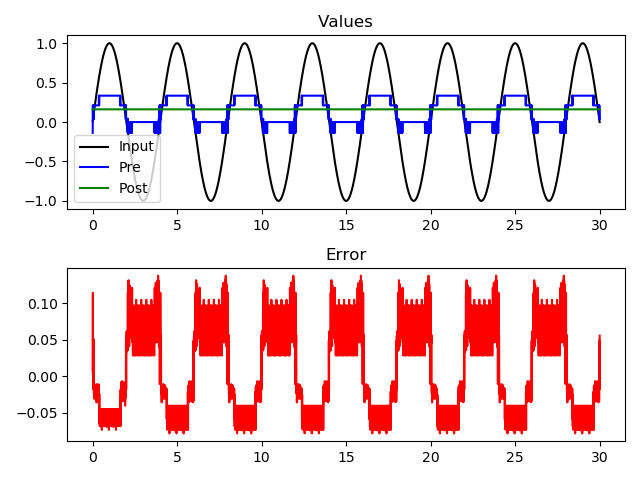
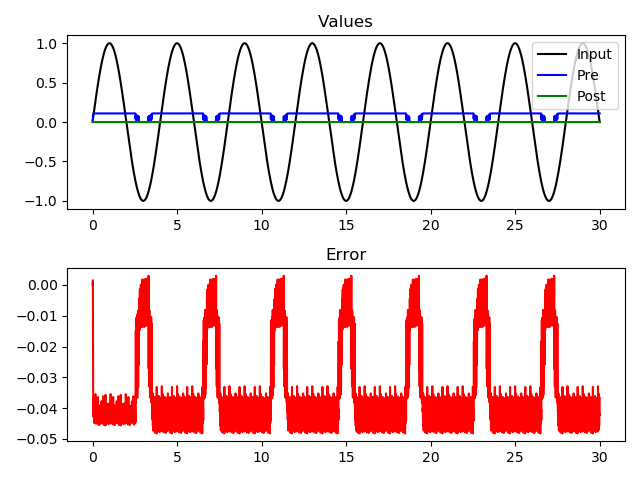
What I don’t see is a correspondent change in the value represented by post:
Am I missing something basic? Or is the error probably something more fundamental that I should look into?
Looking at the plots, it looks like your memristor conductances are relatively constant after the first period of the input (4s). So we wouldn’t really expect to see the post values changing after that point. The output of post might be changing within that first 4s, but it’s hard to tell (since we don’t have any previous points to compare to).
However, you can confirm that modulating the conductances is affecting the output of post, by commenting out the line
self.R += k * c * self.r1 * self.n ** (c - 1)
(so the conductances never update). Then you’ll see that the output of post is very different than if the conductances are updating.
So, the question is why your conductances stop changing after the 4s mark (which I don’t know enough about memristors to say). But modulating the conductances does in fact alter the output of post in your code.
Ok, thanks again. it’s good to know that the error is not in Nengo, at least
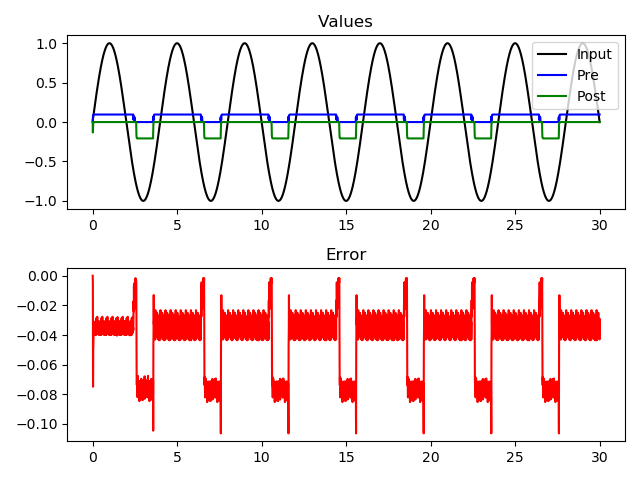
Edit: interestingly, even though the weights are now correctly updating (see first fig.), the outputs of the post population still seem unchanging (see second fig.). Am I just setting up my probes wrong? Or is the input encoder to post somehow modulating the population? (if that’s even a thing, I don’t think so but I can think of no other explanation). Or should I maybe not be normalising my weights to the (0,1] range?
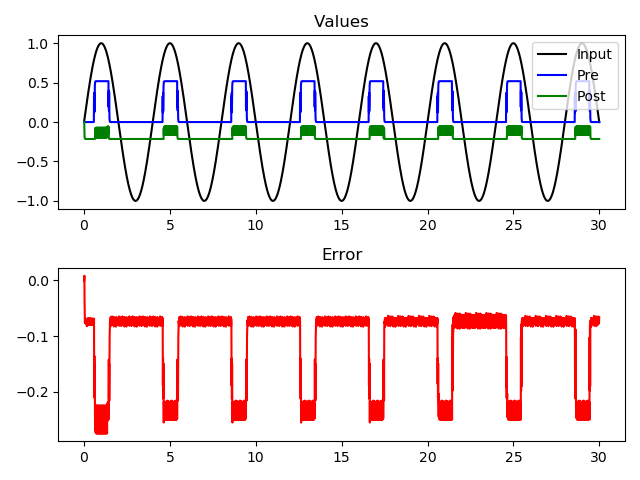
Edit 2: Crazily, I actually seem to get a better fit by generating a random number in the range (0,1] as the memristor conductance when the learning rule has decided that that particular memristor should be updated.
Doing so returns large weight values - because of how the system is set up - so I’m actually thinking that I’m seeing no learning because of a scaling problem in my weights. Are there any guidelines or rules of thumb on the sizing of the weights?
Edit 3: It does seem to be a scaling issue, as multiplying the outputs by 10^4 leads to learning in certain cases, but I would not have expected this. How do the built-in learning rules deal with such issues?
Yes it looks like your weights (conductances) are all very small (~1e-7), so your output is correspondingly very close to zero (making it hard to see any learning that is occurring in those plots). Is that expected in your model? If not, I would look into why your weights are being driven to those tiny values. If it is expected, then your model may just be working as expected. There’s nothing that says a model’s output has to be in the -1–1 range (unless that is required in your application). You’d just have to change the scale on your plots so that you can see what is going on within the range of your outputs.
But how do the built-in learning rules deal with this scaling? From what I can see when using one of those, the ‘post’ population, in general, does not have to worry about rescaling its inputs to match those of ‘pre’s output. What happens is that the representation in ‘post’ is “automatically” on the same scale of that in ‘pre’.
The other learning rules are generally set up in such a way that the weights aren’t driven to tiny values. E.g., if you are using a PES learning rule, it has an error signal which drives the output to some target value. So the weights will naturally adjust, based on that error signal, to the appropriate magnitude so that the output matches the target. If the weights are too small, then the error will increase, causing the weights to increase in magnitude. There isn’t any explicit scaling in the learning rules other than the normal learning process.