I am trying to learn how to implement my own learning model in Nengo by reviewing all of the following code:
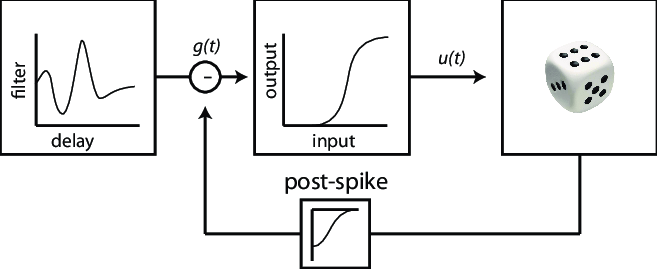
My end goal is to implement a Generalized Linear Neural Model described best by this figure, where the dice represents a probability to obtain a spike:
However, I cannot seem to get a grasp of how these functions work and what logic I am supposed to place in each function. For example, where do I place the logic for my activation function (sigmoid, originally I though this was the rates function), how do I use the step_math function to feedback the post-spike information, what does the max_rates_intercepts do, how does the LIF model described in the code work, etc. It seems I like lack some foundation as I am new to Nengo and only have studied the examples in the user guide and this code before attempting to program this neural model. Is there more material I can study to get a better understanding, preferably video tutorials or a step by step explanation (more in-depth than just the code) of how to implement a neural model?
I have posted other topics here before for a better understanding of this and other material and have understood it but I think I need a further understanding.
Could you give some more details on the model? For instance, how is the filter described (e.g., as a transfer function, a state-space model, or some convolutional kernel)? What is the form of the static input-output response curve (e.g., a sigmoid)? And does the dice-roll represent a Poisson generator? Some of these details might matter in providing guidance as to the easiest route.
Also, what do you plan on doing with this model? Do you intend to create populations of them, with each neuron having a different encoding filter? And do you need to learn the optimal weights to have the population represent some particular vector over time?
The GLM neural model I am currently trying to implement will be used in a classifier network (using the MNIST data set, distinguishes between the handwritten numbers 0 to 9). This network will not be the conventional MNIST network it will be a directly 2 layer network with 784 neurons in the first layer and 10 neurons in the second layer. The model has the following specifications (explained using the image posted in the original post as a reference):
The g(t) representing the membrane potential of the postsynaptic neuron will be will be determined by past spiking activity of the pre-synaptic neuron (X) and the post-synaptic neuron (Y, this post-synaptic spiking history is shown as the post-spike in the diagram which feeds back) as well as the bias of Y (B). Where the activities X and Y will be multiplied by the identity matrix (I) and the respective learnable weights (W). In other words, g(t) = (X * I * W) + (Y * I * W) + B.
In order to determine u(t), g(t) will be mapped to the sigmoid activation function.
u(t) will then be weighted by a probability to generate a spike via a Bernoulli random variable (which I was going to implement as a random number generator). The output of this processing will be output of this model.
I am having a hard time translating this into something that can be represented in Nengo. If you need any clarifications, please let me know. I am still in the process of figuring this out and any suggestions or hints would be greatly appreciated.
Bullet points 2 and 3 should be achievable by a fairly simple custom neuron model that defines the step_math function.
However two things are still unclear:
It looks like a filter (i.e., convolution over time) is being applied to the feedback post-spike. What is this filter? A lowpass (i.e., exponential decay)?
What is the filter driving the postsynaptic neuron (i.e., the squiggly line in the left-most box)? Is this filter the same for each postsynaptic neuron?
Bullet point 1 might be a little trickier as you may need to implement a custom unsupervised learning rule on full-weight matrices? An example of how to do this can be found below, although there is a bunch of boilerplate in build_bcm and BCM that is also needed. Might make sense to get the GLM working first and then add learning next. We can help you with some of these details.
There are two filters and this mostly has to do with the relation I specified in Bullet Point 1 which is why I would need the most assistance in implementing 1 because like you said Bullet Points 2 & 3 are fairly simple. So regarding the postsynaptic filter and the filter applied to the feedback post-spike;
The filter that is applied in order to produce g(t), the filter that is seen on the far left box, is synaptic kernel filter, alpha. This filter is applied to ALL the pre-synaptic neurons that are connected to the post-synaptic neuron which is producing our spike randomly (Bernoulli random variable). I generalized alpha before by saying g(t) = (X * I * W) + (Y * I * W) + B when it is really g(t) = (alpha * X) + (beta * Y) + B (beta is the other filter you asked to define which I will discuss in the next bullet point). Alpha or the synaptic kernel filter is defined as the matrix multiplication between matrix A and vector W. Matrix A is the identity matrix while vector W are the learning weights of each respective pre-synaptic neuron with length equal to the number of basis functions (in this case the basis function being a raised cosine).
Similarly, beta or the feedback kernel filter is the filter that lies between the post synaptic neuron’s output and the input to the post synaptic neuron’s activation function. This is filter affected the box labeled post-spike and is the box at the bottom of the diagram. It is defined as the matrix multiplication between matrix B and the vector v. Where, B is the identity matrix while vector V is the learning weight of the respective post-synaptic neuron with length equal to the number of basis functions (in this case the basis function being a raised cosine). This filter is applied to each post-synaptic neuron individually in the neural network but is applied to all of them.
If you need any clarifications, please let me know. I am still in the process of figuring this out and any suggestions or hints would be greatly appreciated. I also appreciate the assistance you have given me thus far.
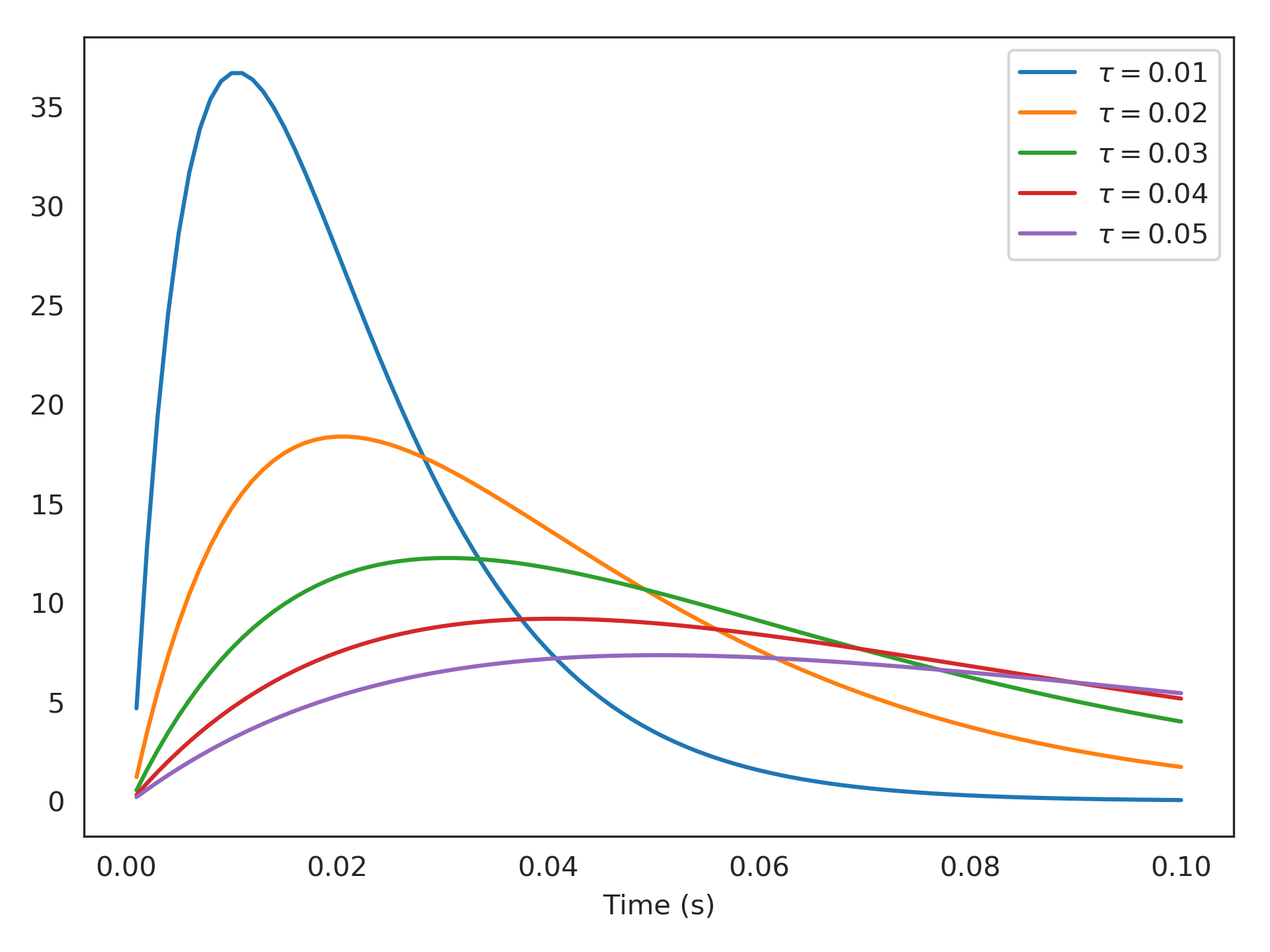
To clarify, when you say “alpha” are you referring to the alpha filter that is common in Nengo/Neuron/etc? Whose impulse function—for various \tau time-constants—is visualized below:
I’m confused as to the form of the filter again here. Keep in mind I’m referring to the temporal filtering of the spikes. Is this what you mean by raised-cosine: Raised-cosine filter - Wikipedia? If so how would you make this filter causal? In its basic form, this is a non-causal filter that requires knowledge of the future.
No, alpha was just referring to the symbol I used to represent it in the equation for g(t), nothing but a symbol. Additionally, this design I am implementing for the GLM neural model is based off the following research paper:
Section 2 labeled Spiking Neural Networks with GLM Neurons is the design I am referring to when describing this you can also see there is a similar figure for the model. Towards, the end of the section there is a description of SK and FK filters which I am not so sure I described clearly enough for your understanding. However, the paper’s description is exactly what I am trying to achieve.
Okay I think I’m getting this now. So both the input and recurrent filters are a linear combination of the basis functions from https://www.nature.com/articles/nature07140 where the coefficients of the linear combinations are specific to each neuron and learned by some learning rule.
Do you know how far back in time these filters need to go? Figure 3 shows just 8 time-points – is this how many are needed? Maintaining 8 steps in a rolling window (queue) wouldn’t be so difficult. This could be done by adding an (n, 8)-dimensional state matrix to the neuron model, that rolls the second axis each time-step.
The part that sounds difficult to me is that the parameters of your filters ($\alpha$ and $\beta$) need to change on-the-fly, and, in order to apply the learning update, the model must have access to the entire presynaptic activity vector?
Do you have any reference code in any language for this model? I think the most straightforward thing to do at this stage is to just write this as a plain Python loop using numpy vectors and matrices. This would help ensure you know exactly what you want it to do, and I don’t expect it would be too many lines of code. Or is there some aspect of Nengo that you feel would be useful for next step(s)? In the mean time I’ll see if I can get anyone else on this to help.
I would like to leave the amount of time points needed for the filters as a parameter for the learning model however, if this becomes to complex I think leaving it at 8 like the example shows will be fine. I believe that is correct the model must have access to the entire presynaptic activity vector. Additionally, alpha and beta were the main conceptual issues I had when trying to implement this in Nengo’s learning model, I couldn’t derive a flow of logic especially since I couldn’t develop a way to access the entire presynaptic activity vector and put the weights in as parameters to the step_math function. Especially, since I didn’t know how often the function’s parameters gets updated, I assumed every simulation timestep.
I have not tried developing any reference code in any language for this model, I was told that Nengo was the best place to start which seemed logical at the time. I will try to develop the reference code as soon as possible. The aspect of the code that will be introduced later is the learning & decoding discussed later in the research paper. The backend for the simulation I will be using, will be Nengo Loihi, I am not sure whether this changes anything however, I was sure from reading the documentation that using the Loihi backend would not change my implementation if I developed it with the normal Nengo backend first.
Once again, I appreciate all your assistance on my current issue with developing this learning model.
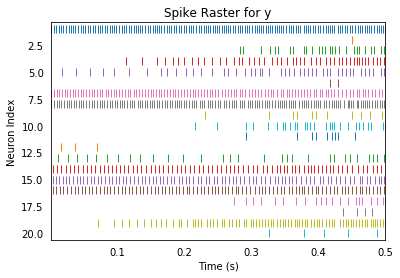
As a work-around one can always connect the two neural ensembles together using a Node that does whatever it wants each time-step. For example, here is how we can make the connection weights vary as a function of time:
import nengo
import numpy as np
class CustomLogic(object):
def __init__(self, in_size, out_size, rng=np.random):
# initialize whatever state you want here
self.in_size = in_size
self.out_size = out_size
self.W = rng.randn(
self.out_size, self.in_size) * 1e-3
def __call__(self, t, a):
# called each time-step with the entire
# presynaptic activity vector, and outputs
# the postsynaptic currents
# you can do whatever you want here
return t * self.W.dot(a)
seed = 0
rng = np.random.RandomState(seed=seed)
with nengo.Network(seed=seed) as model:
# note each neuron has a random gain and bias by default
x = nengo.Ensemble(50, 1)
y = nengo.Ensemble(20, 1)
custom = nengo.Node(
size_in=x.n_neurons,
output=CustomLogic(x.n_neurons, y.n_neurons, rng=rng))
nengo.Connection(x.neurons, custom, synapse=None)
nengo.Connection(custom, y.neurons, synapse=None)
p_y = nengo.Probe(y.neurons, 'spikes', synapse=None)
with nengo.Simulator(model, dt=0.001) as sim:
sim.run(0.5)
import matplotlib.pyplot as plt
from nengo.utils.matplotlib import rasterplot
plt.figure()
plt.title("Spike Raster for y")
rasterplot(sim.trange(), sim.data[p_y])
plt.xlabel("Time (s)")
plt.ylabel("Neuron Index")
plt.show()
This is assuming a number of things about your implementation with the normal Nengo backend, such as:
It uses only ensembles of LIF or IF neurons for the neurons that are to run on the board
It does not define any custom neuron models or learning rules
Any custom nodes will be run on the host (off the chip)
With the reference Nengo backend, the builder rules specify how to compile each object onto a CPU. These rules must be redefined for each backend. We are working hard to relax some of these constraints and automate this the best we can. However, some of the limitations are due to the architecture of Loihi itself, and thus cannot be relaxed on the current hardware. So for now, support is primarily focused on building Nengo models that use the simple spiking models that don’t define custom builder logic.