Hello everyone,
This is my first post in this community and I hope that I am not horribly ignorant to the forum guidelines by posting my question here.
I have been using nengo and nengo_dl in my latest research project, and based on my limited experience so for I generally think both are great tools. I come from an AI background and have worked on several deep learning projects (primarily Pytorch) in the past. I am hoping to use nengo to develop a spiking network for model predictive control (MPC). In my typical workflow, when I train a model, I also evaluate it’s performance continuously during the training process on a separate chunk of the dataset. My standard training loop looks something like this:
- Initialize the model and training / validation data
- Load latest weights, train for an epoch and save the new weights
- Load latest weights and evaluate the model
- Repeat steps 2 and 3 until some condition is reached (max epochs or loss below X)
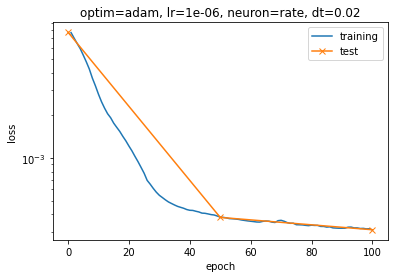
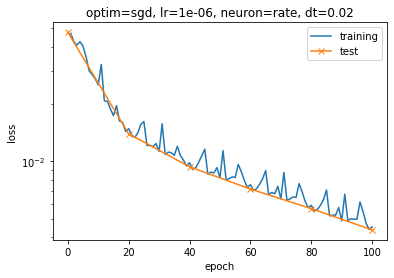
When trying to apply this method to my nengo model, however, I noticed that when I train for some epochs, say 5, and then with another simulator object want to continue training with the same parameters, I start back at a higher loss than I left off. Below, I added an image of these results where I first train for 50 epochs, and then train the same model again for another 50 epochs. These are made with the Adam optimizer, but the effect also happens when using SGD but to a lesser extend. This also occurs when I do not even do an evaluation (step 3) in between. I think this might have something to do with the state of the optimizer? But I do use the exact same optimizer object for both training steps.
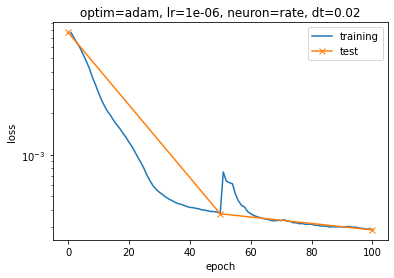
In the end, I would like to be able to look at validation results during training without this influencing the results I get. In other words, I expect the same outcome if I train once for 100 epochs in a single simulator object, or 100 times for 1 epoch with individual simulator objects. I use separate objects because my current understanding it that they “close” and are not “reusable” in nengo.
I have created a working example that produced these results in a jupyter notebook and it is available right here:
https://drive.google.com/file/d/1vXJj0JD_f6odaUiCQdB_4KP49KJANhAS/view?usp=sharing
I would be very happy about any sort of insight on 1. why this behavior occurs, and 2. how I can avoid it. Any assistance in this regard is highly appreciated. Perhaps other people have run into this or a similar issue before and there is a “standard” learning loop that works in nengo_dl that I am unaware of? The examples given in the official documentation do not seem to cover this - only how to indeed save the weights and use them later, which I believe I implemented correctly.
Thank you very much for your help and stay safe,
Justus