I know this may sound weird,
but I’m trying to apply PES online learning rule on ensemble (or EnsembleArray) to learn the association of the SPs.
e.g: feed pointer ‘A’ into an ensemble and output pointer ‘B’.
Then I found out that this problem involves different levels in Nengo, SPA and network level.
So I’ve got a hard time on figuring out how to integrate two.
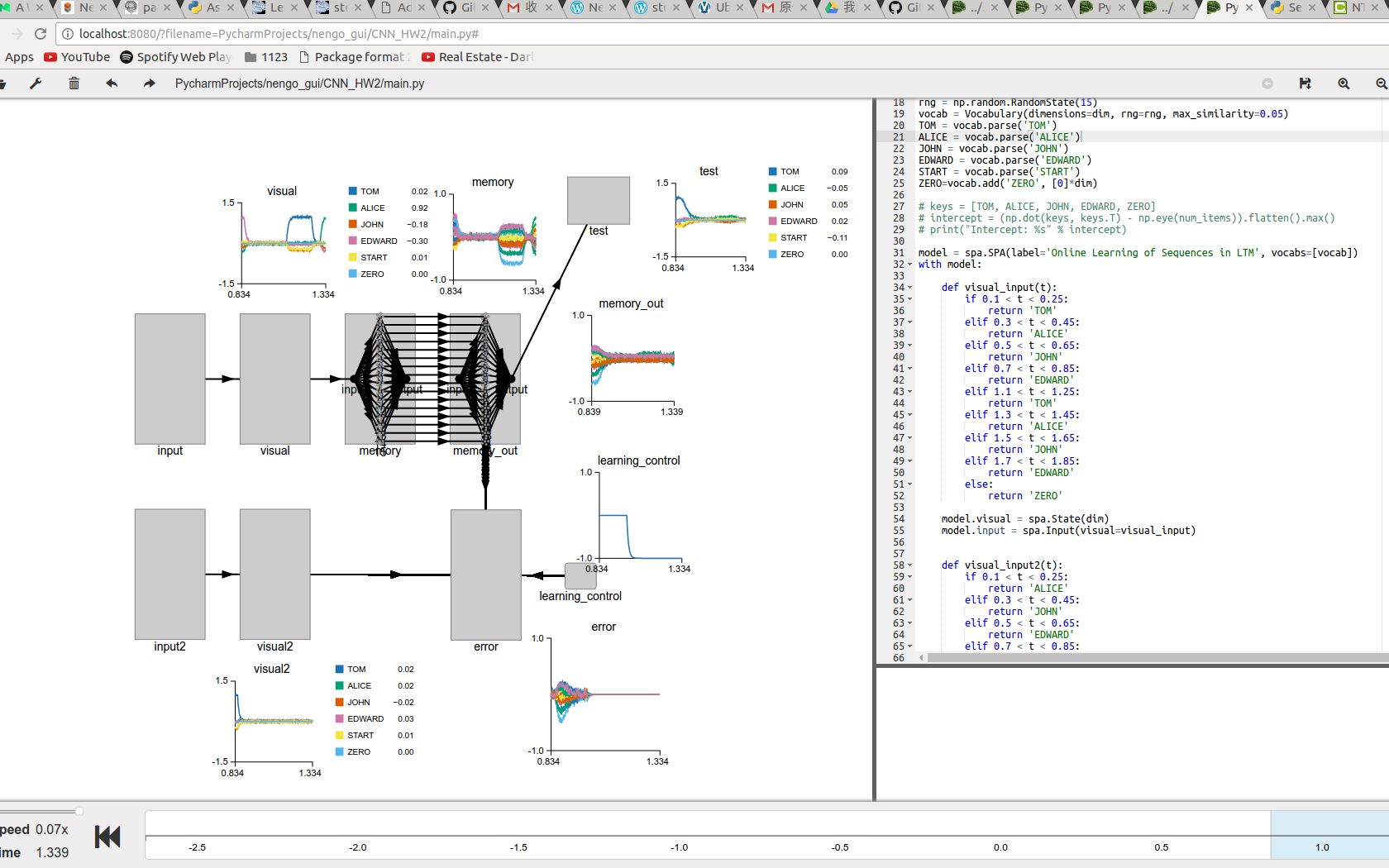
Finally, I did managed to run the sim in GUI.
But doesn’t work as I expected.
I’ll update the simulation result later. --DONE
the code is as below:
# Setup the environment
import numpy as np
import nengo
import nengo.spa as spa
from nengo.spa import Vocabulary
from nengo.spa import BasalGanglia
from nengo.spa import Thalamus
from nengo.dists import Uniform
dim=16 # Number of dimensions
N=32 # Neurons per dimension
N_conv=64 # Number of neurons per dimension in bind/unbind populations
N_mem=32 # Number of neurons per dimension in memory population
ZERO=[0]*dim # Defining a zero vector having length equal to the number of
# dimensions
#Creating the vocabulary
rng = np.random.RandomState(15)
vocab = Vocabulary(dimensions=dim, rng=rng, max_similarity=0.05)
TOM = vocab.parse(‘TOM’)
ALICE = vocab.parse(‘ALICE’)
JOHN = vocab.parse(‘JOHN’)
EDWARD = vocab.parse(‘EDWARD’)
START = vocab.parse(‘START’)
ZERO=vocab.add(‘ZERO’, [0]*dim)
model = spa.SPA(label=‘Online Learning of Sequences in LTM’, vocabs=[vocab])
with model:
def visual_input(t):
if 0.1 < t < 0.25:
return 'TOM'
elif 0.3 < t < 0.45:
return 'ALICE'
elif 0.5 < t < 0.65:
return 'JOHN'
elif 0.7 < t < 0.85:
return 'EDWARD'
elif 1.1 < t < 1.25:
return 'TOM'
elif 1.3 < t < 1.45:
return 'ALICE'
elif 1.5 < t < 1.65:
return 'JOHN'
elif 1.7 < t < 1.85:
return 'EDWARD'
else:
return 'ZERO'
model.visual = spa.State(dim)
model.input = spa.Input(visual=visual_input)
def visual_input2(t):
if 0.1 < t < 0.25:
return 'ALICE'
elif 0.3 < t < 0.45:
return 'JOHN'
elif 0.5 < t < 0.65:
return 'EDWARD'
elif 0.7 < t < 0.85:
return 'TOM'
else:
return 'ZERO'
model.visual2 = spa.State(dim)
model.input2 = spa.Input(visual2=visual_input2)
model.memory = nengo.networks.EnsembleArray(n_neurons=N, n_ensembles=dim)
model.memory_out = nengo.networks.EnsembleArray(n_neurons=N, n_ensembles=dim)
nengo.Connection(model.visual.output, model.memory.input)
model.error = nengo.networks.EnsembleArray(n_neurons=N, n_ensembles=dim)
model.learning_control = nengo.Node(output=lambda t: -1*int(t >= 1))
voja = nengo.Voja(post_tau=None, learning_rate=5e-2)
model.conn_in = list()
model.conn_out = list()
for i in range(dim):
# Learn the encoders/keys
# model.conn_in.append(
# nengo.Connection(model.memory_in.ensembles[i], model.memory.ensembles[i],
# synapse=None, learning_rule_type=voja)
# )
nengo.Connection(model.visual2.output[i], model.error.ensembles[i], transform=-1)
nengo.Connection(model.memory_out.ensembles[i], model.error.ensembles[i], transform=+1)
# Learn the decoders/values, initialized to a null function
model.conn_out.append(
nengo.Connection(model.memory.ensembles[i], model.memory_out.ensembles[i],
learning_rule_type=nengo.PES(1e-3), function=lambda x: np.zeros(1))
)
nengo.Connection(model.error.ensembles[i], model.conn_out[i].learning_rule)
nengo.Connection(model.learning_control, model.error.ensembles[i].neurons, transform=[[10]]*N)
High dimension ensemble isn’t really efficient at presenting SP, so after realized this phenomenon, I switched to EnsembleArray, which I’m not sure PES rule still work…
Or maybe I should build the whole model in nengo.network level? I spotted some examples demonstrate online learning in network level and they worked. I’m confused…
Does manipulating intercept of neurons critical to PES learning?
Maybe the nonlinear transformtion across dimensions in an ensemble is a MUST to perform hetero-association task, which is not capable in ensembleArray?
That’s correct!
I was aware of that.
I know that if I need association memory I can just explicitly defined it.
But l was interested in learning rules on the fly.
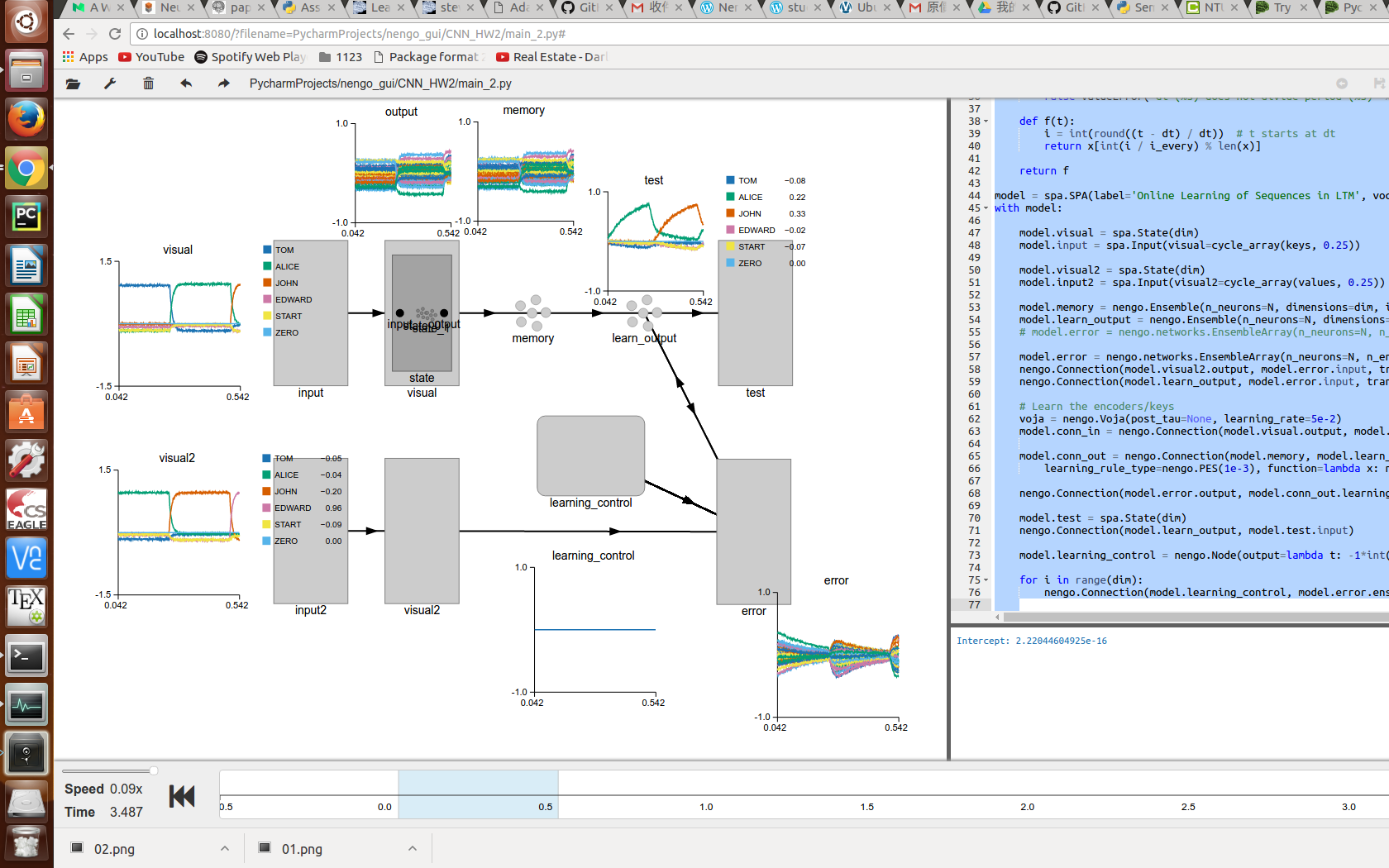
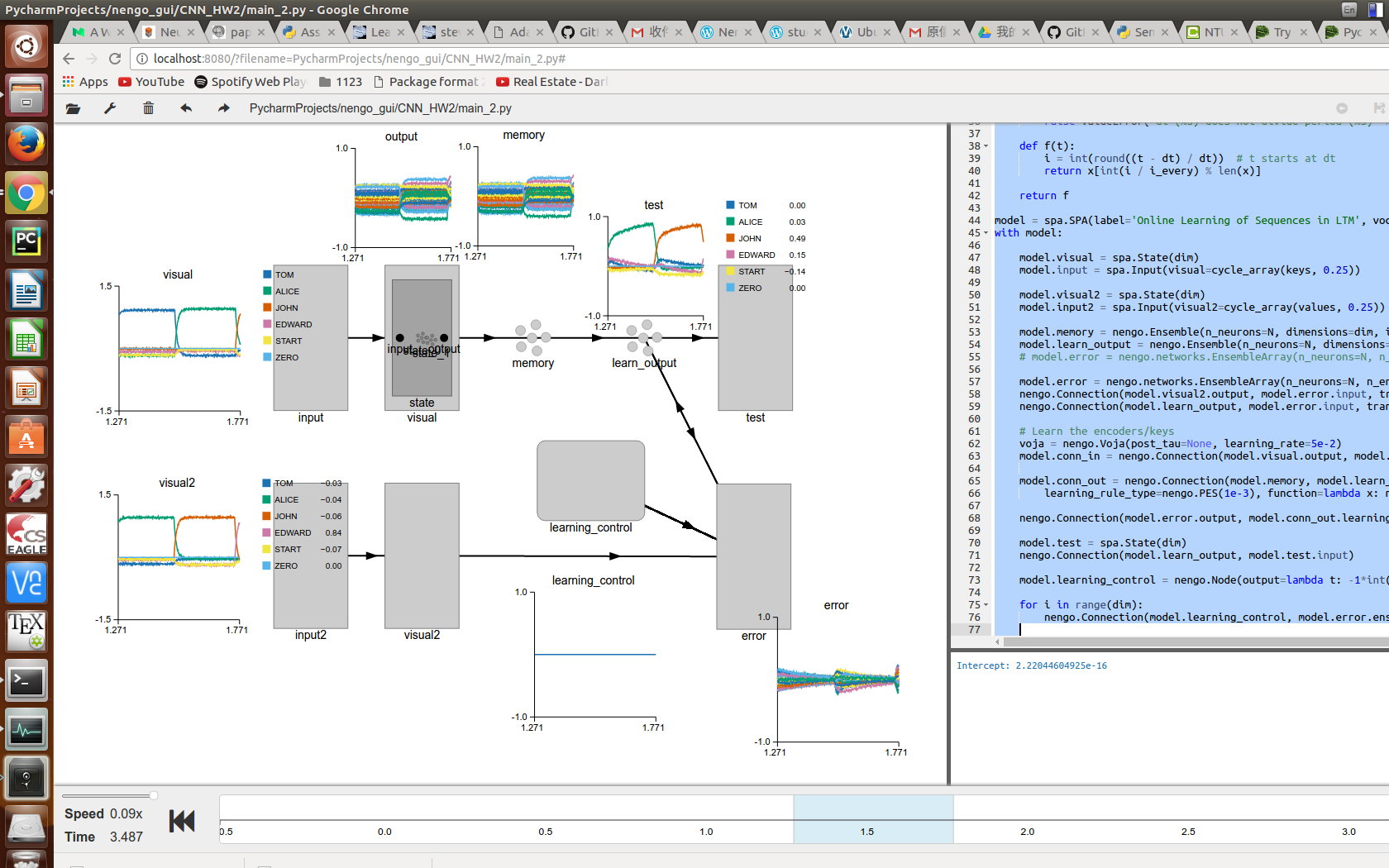
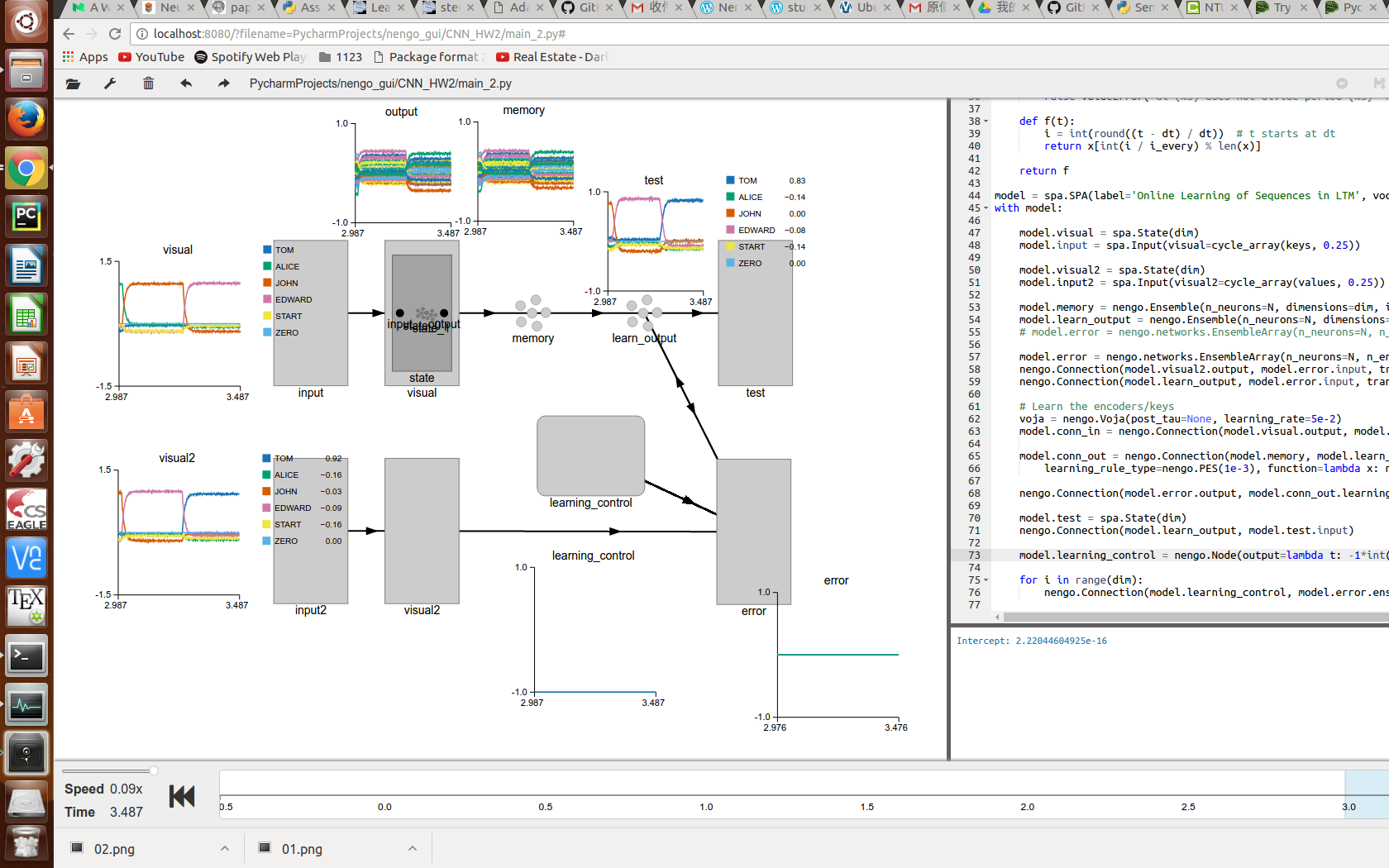
I have done some tweaking and got some improvement.
I’ll update later.
multi-dimensional native ensemble as memory for learning. (no EnsembleArray)
specify the interception of the learning neurons.
lower the SP dimension.
increase the number of neurons per dimension.
discard Voja learning rule at the conn_in for stabler performance.
learning the association multiple times.
# Setup the environment
import numpy as np
import nengo
import nengo.spa as spa
from nengo.spa import Vocabulary
from nengo.spa import BasalGanglia
from nengo.spa import Thalamus
from nengo.dists import Uniform
dim=32 # Number of dimensions
N=1024 # Neurons per dimension
#Creating the vocabulary
rng = np.random.RandomState(15)
vocab = Vocabulary(dimensions=dim, rng=rng, max_similarity=0.01)
TOM = vocab.parse(‘TOM’)
ALICE = vocab.parse(‘ALICE’)
JOHN = vocab.parse(‘JOHN’)
EDWARD = vocab.parse(‘EDWARD’)
START = vocab.parse(‘START’)
ZERO = vocab.add(‘ZERO’, [0]*dim)
keys_v = np.zeros([len(keys[:-1]), dim])
for i in range(len(keys[:-1])):
keys_v[i] = vocab.parse(keys[i]).v
intercept = (np.dot(keys_v, keys_v.T) - np.eye(len(keys[:-1]))).flatten().max()
print(“Intercept: %s” % intercept)
def cycle_array(x, period, dt=0.001):
“”“Cycles through the elements”“”
i_every = int(round(period / dt))
if i_every != period / dt:
raise ValueError(“dt (%s) does not divide period (%s)” % (dt, period))
def f(t):
i = int(round((t - dt) / dt)) # t starts at dt
return x[int(i / i_every) % len(x)]
return f
model = spa.SPA(label=‘Online Learning of Sequences in LTM’, vocabs=[vocab])
with model:
Yes, if the function you’re trying to learn is multidimensional (as it is in the case of an associative memory), then you need to represent all the input dimensions in a single ensemble.
Consider a super simple associative memory, learning an XOR task:
If we broke up that input into separate dimensions (e.g., by representing it in an ensemble array), then, e.g., the first dimension would be trying to learn a function like:
[0] -> [0]
[0] -> [1]
[1] -> [1]
[1] -> [0]
That isn’t going to work well, because we’re asking the ensemble to map the same inputs to different outputs (when it sees a [0], how is it supposed to know whether it should output [0] or [1]?).
So, the general rule is that when you’re learning some function, the ensemble you’re learning on needs to be representing all of the inputs to that function.
However, as always there are some exceptions to that rule. For high dimensional representations there’s often a lot of overlapping information between dimensions. So, for example, if you were representing a 256 dimensional vector in an EnsembleArray with 8x32 dimensional populations, it might still be possible to learn something useful. The number of dimensions you need in each ensemble will depend on the structure of your inputs and outputs, so you’d probably just have to play around to see what works.
Your example is totally clear, I got it now… Thanks a lot!
Associative Memory learning example
Yes, I built my model with that example as reference, that really helped.
But the point of my experiment is to try on semantic pointers and incorporate with rest of the SPA module.
You can think of the intercept in this case as controlling the sparsity of the neural representation. When learning an associative memory the sparsity is important, as it controls the amount of “cross-talk” during learning. High intercepts means that each neuron responds to a very select number of inputs, so each neuron is learning an isolated part of the associative memory (e.g., one cell in the table if this were a standard table-based lookup memory). Low intercepts means that neurons are responding to a wide range of inputs, so they will generalize better to novel inputs that weren’t in your training data. So again that’s something that you need to play with to figure out what the right setting is for your particular data/task.
Is that the reason for the ensemble in the spa.State module are divided into ‘state_n’ group, then encapsulated with input output nodes as interface.
When I check the dimension of the interfacing node, they were the same dimension as the SP, but the ensembles inside aren’t. That was confusing for me.
Followed up question:
so maybe I could try to make an online learning memory module with few lower dimension ensembles to learn the association of high dimension SP?
Yes that is the same idea, the subdimension parameter of spa.State is controlling the size of each ensemble in the EnsembleArray, so e.g. spa.State(dimensions=64, subdimensions=16) will give you an EnsembleArray representing 64 dimensions via 4 16-dimensional ensembles.
In that case it isn’t really done to facilitate learning, it’s to help with the normalization of the vectors. But it’s the same idea that for high dimensional representations we can get away with representing some subset of the dimensions in each ensemble, due to the overlapping information between dimensions.