Hi @khanus
I finally had the time to take a look at your code to figure out what was wrong with it. As it turns out, it was a rather simple fix (but I only discovered it after taking apart pretty much your entire notebook…  )
)
The offending cell was the one with this code:
with nengo_dl.Simulator(net, minibatch_size=100, unroll_simulation=16) as sim:
# Load the saved simulator parameters
sim.freeze_params(net)
...
As it turns out (and I am not familiar with NengoDL to have spotted this quickly), freeze_params doesn’t actually do what you want the code to do. Looking at your code, I believe you intended that block of code to load up whatever parameters you had saved during the network training run (i.e., in the cell above, after the sim.fit call)
However, what the code in your notebook actually does is to create a new simulator object, and call the freeze_params function on net. Since your notebook creates an entirely new simulator object, the network is re-initalized with random weights, effectively removing the effect of the training.
** As a side note, what the freeze_params function does is to take whatever had happened in that sim context block (i.e., anything within an as sim block), and transfer it back into the net object. If you had called the freeze_param function in the previous cell, it should have worked. But, since you created a new sim context block before calling freeze_param, NengoDL made a new simulator (and reinitialized everything) before the freeze_param call.
Fixing your code is simple – instead of using freeze_params, use the load_params function, like so:
with nengo_dl.Simulator(net, minibatch_size=100, unroll_simulation=16) as sim:
# Load the saved simulator parameters
sim.load_params("./lmu_params")
...
Another thing I did to get your code to work is to restructure the training output data. I noticed that it was using the correct array dimensions, so I added this:
# this flattens the images into arrays
train_outputs = train_images.reshape((train_images.shape[0], -1))
test_outputs = test_images.reshape((test_images.shape[0], -1))
# convert outputs into temporal format
train_outputs = train_outputs[:, None, :]
test_outputs = test_outputs[:, None, :]
And modified the training to do this instead:
sim.fit(train_images, train_outputs, epochs=n_epochs)
I’ve attached my version of the LMU auto-encoder network below. Note that in my notebook, I have two variants of the auto-encoder network. The first being the LMU version that you were trying to implement, and the second being a feed-forward version that is based off this NengoDL example. I used the feed-forward version to debug the rest of the code in the notebook, since it was way faster to train and test.
sequential_lmu_autoencoder.ipynb (44.6 KB)
Here’s an example input-output pair from the test dataset using the LMU auto-encoder network that had been trained on the 60,000 image training set for 1 epoch.
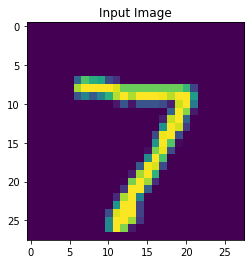
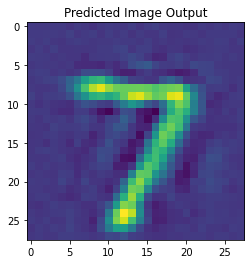
There are definitely more improvements you can make to the code, but I think this should give you a good start.
Oh, and apologies for the wait!