I am new to SNN and nengo. I need to implement a Reservoir with spiking neurons (basically, LSM) but I am struggling to understand how to do it.
My input is an analog signal that I convert into UP and DOWN spikes with an encoding algorithm. As far as I understand, nengo.Node is used to map a continuous input, but can not be used with spike array (1D, composed of 0,1,-1). Should I use nengo.Ensemble to define my input ?
Then, I imagine that I have to use nengo.Ensemble for the Reservoir. Can I tune the network topology (3D coordinates of the neurons, space between them, etc.) ?
Finally, can nengo.Solver be used for the readout layer ?
I didn’t find any code implementing LSM with nengo, does anyone have something to share with me?
Thank you in advance for taking the time to answer
Edit : I do have more general questions :
What should I use for the weights of the connections : synapse or transform ? I thought that weights were representing synapses but it seems that code examples use transform for it.
How can I run the simulation X times (for the X examples in my train set) ? Because I need to modify the input node at each iteration and reset the simulation too I imagine.
I’m not super familiar with reservoir computing to fully answer your questions, but I can answer your more generic Nengo related ones.
You can use Nengo nodes to provide a spiking input. The spikes themselves need to be either on (is spike) or off (no spike). For each timestep in the data series, if there is a spike, the output of the node should be 1/dt, where dt is the simulation timestep. The default simulation timestep is 0.001s, so if you don’t change it a “default” spikes should have an amplitude of 1000. The following code demonstrates how you would do this in a Nengo network (although, in the code below, it’s just sending a random spike array to the Nengo ensemble): test_spike_in.py (1.2 KB)
Just to demonstrate that you can use nengo.Nodes to transmit meaningful data. Here’s another bit of example code: test_spike_in2.py (1.9 KB)
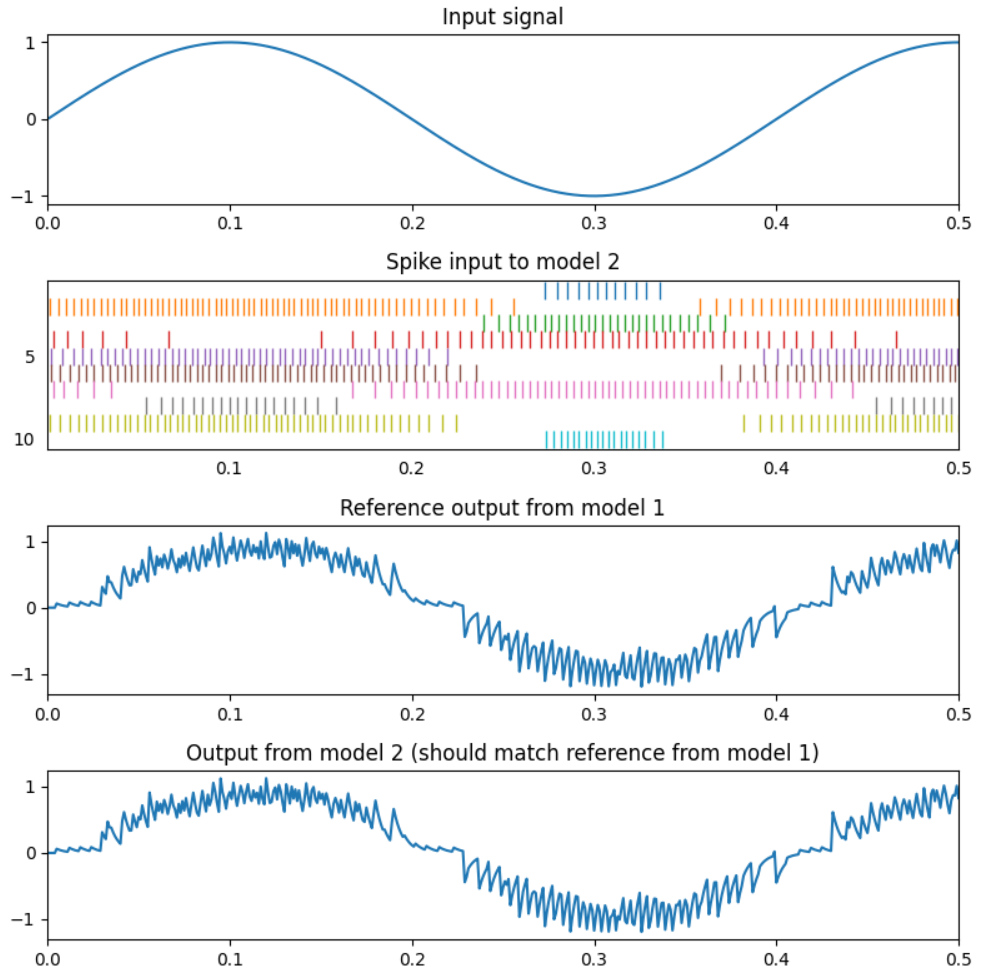
In this case, the code is comprised of 2 separate Nengo models. Spikes are recorded from an intermediate ensemble of the first model, and this is used as input to an identically configured ensemble in the second model. In essence, in the second model, ens1 is removed and replaced with a node that produces the spiking output recorded from the first model. If all works properly, the output from model1 and model2 should be identical (as shown in the figure below):
As the nengo.Ensemble object is essentially a collection of neurons, I think you’ll want to use it for the reservoir. However, Nengo objects do not have any topology information available to them. They are generally point neurons with no spatial component (i.e., there is no distance-related temporal delays of any kind in Nengo). I’m not familiar enough with reservoir computing networks to know exactly how this limitation will impact your implementation in Nengo. I’ll ask some of the Nengo devs to see if they have any insights.
I presume that the “readout layer” is typically a bunch of neurons as well? If that’s the case, then you’ll also want to use a nengo.Ensemble object for the readout layer. From my quick read of reservoir computing networks, it looks like the connections between the reservoir and the output layer are neuron-to-neuron connections, so you’ll want to do something like this:
with nengo.Network() as model:
res = nengo.Ensemble(...)
output = nengo.Ensemble(...)
# Neuron-to-neuron connection
nengo.Connection(res.neurons, output.neurons, transform=<weights>)
The crucial thing in the code above is how to determine the weights used in the connection. I presume that there’s some learning algorithm involved with the reservoir computing, so you’ll need to do the same in Nengo.
What is nengo.Solver used for?
As a side note, nengo.Solver is a special purpose object that is used to tell Nengo what solver (weights solver) to use when defining weights for specific nengo.Connection objects. You can read more about them here. There is also an example in the test_spike_in2.py code I included above:
If you want to know why Nengo uses solvers to determine weight matrices, I’d advise you to watch this tutorial on the Neural Engineering Framework (NEF). The NEF is the algorithm Nengo uses under the hood to allow neural ensembles to perform seemingly complex functions without the need for the typical learning phase.
If you want to specify the weights of a connection, you’ll want to use the transform parameter. The synapse parameter is used to determine the post-synaptic filter (similar to a PSC, if you are familiar with biological neurons) to apply to the connection. By default, Nengo uses the exponential synapse, but this can be changed using the synapse parameter. I should note that Nengo only allows 1 synapse type per connection. If you want different synapse types (or different synaptic time constants) per neuron, you’ll need multiple connections.
To run your simulation multiple times, all you need to do is to call the with nengo.Simulator(...) context block multiple times. Each time that context block is called, a new Nengo simulator object is created, and this in turn builds a new Nengo model for that simulation. Note that unless specified (typically with a seed), each Nengo simulation will randomly generate the parameters (gains, biases) of any neural ensembles in the model. This is why in my example test_spike_in2.py code, I seed one of the ensembles (to ensure that between the two models, they have the same parameters).
Because each simulation run rebuilds the Nengo model, you can change the model between simulation runs. This can be done, for example, to update connection weights between each run.
Some notes
In Nengo, code is split up into 2 distinct parts: the model description, and the model simulation. The model description is anything contained within the with model: context block. Nengo will read this context block to determine the structure of the Nengo model, but no weights are solved for, and no neuron parameters are set at this stage.
The model simulation is anything contained within the with nengo.Simulator(): context block. The first step in the simulation is for Nengo to take the model description and build the simulator object. This is where Nengo will determine the neuron parameters and solve for the connection weights. Finally, only when the sim.run() call is made does Nengo actually step through the simulation and generate the spike data (and etc.) in the model.
Thank you very much for your answers, it was really helpful !
I still have some questions :
Just to demonstrate that you can use nengo.Nodes to transmit meaningful data. Here’s another bit of example code: test_spike_in2.py (1.9 KB)
So it means that nengo isn’t doing spike encoding before feeding inputs to neurons (if I use a spiking neuron model) ? How is it possible ?
I presume that the “readout layer” is typically a bunch of neurons as well? If that’s the case, then you’ll also want to use a nengo.Ensemble object for the readout layer.
Actually, it can be multiple things such as a layer of formal neurons or a machine learning algorithm. If I want to use a layer of formal neurons, how can the spikes output of a reservoir be fed to the readout, as spikes are event-based ?
As a side note, nengo.Solver is a special purpose object that is used to tell Nengo what solver (weights solver) to use when defining weights for specific nengo.Connection objects
So the purpose of solvers is to tune the weights to reach an objective function ?
Regarding the reservoir, is it possible to create random connections ? It seems that nengo.Connection accepts only neurons and I want to randomly connect (or not) neurons of an ensemble between them.
Also, can I define my model and just change the input for each sample in my train set (typically, create a node and connect it to the model) without redefining the whole model ?
Finally, why can we add synapses to probe ? Isn’t the goal of probes to collect data from what it is connected to ? So why would we modify this data ?
Again, thank you very much for your time, I am getting a better understanding now
Before I answer your new questions, I’ll address a question you had before that I didn’t answer:
I spoke to my colleagues and they informed me that @tcstewar, @arvoelke and @drasmuss have all worked on some version of a reservoir computing network in Nengo before. In order of recency, @tcstewar has code that works with the lastest-ish version of Nengo. @arvoelke’s code has only been throughly tested with Nengo 2.0, and @drasmuss has code that only works with Nengo 1.4.
@tcstewar has a Jupyter notebook here that steps through how to set up a network with recurrent neuron-to-neuron connections. While this is not specifically an LSM, it can serve as a basis for an LSM network (since the structures are similar). @arvoelke has perhaps the most comprehensive example here where he constructs a reservoir network in Nengo. However, his code uses custom Nengo code (e.g., his custom Reservoir network) from his NengoLib library and this has only been tested to work with Nengo 2.0. With some work, it may be possible to get his NengoLib reservoir computing network to work in the latest version of Nengo… it may even be possible to extract just the reservoir.py file and use it as a standalone network in Nengo (my quick look at the file don’t reveal anything that would stop it from working with the latest version of Nengo).
The test_spike_in2.py code demonstrates quite the opposite actually. The code is separated into 2 parts. The first part builds and runs a “reference” neural model. The second part uses recorded spike data from the first neuron model as an input signal. In the first neural model, the probe is attached to the neuron output of ens1. Since the input signal is connected to the input of the ens1 neural population, the ens1 ensemble is essentially “encoding” the input into a series of spike trains.
In the second part of the model, the encoded spike train is fed through a weight matrix that “decodes” the spike train into information that ens2 can use as an input. This weight matrix is determined by the NEF algorithm. To learn more about this, I recommend you watch the Nengo Summer School youtube playlist I linked above, or read the documentation here
I’m not entirely clear which layer you are asking about here. Are you asking about the process to record spiking output from an output layer that consists of neurons? In any case, in Nengo, we tend to apply filters to spike outputs to “smooth” them. These smoothed spikes are then fed through a set of weights (known as decoders, or you can think of them as “output” or “readout” weights) that linearly combine these signals into real-valued (no-spiky) signals.
In a sense, yes. However, I would not use the word “tune” as “tuning” implies some sort of learning process. Rather, the solvers use a mathematical algorithm (e.g., Least-squares regularization) to solve for these weights. The process by which this is done is described in the documentation of the NEF.
I recommend checking out these examples to see how Nengo (and the NEF) can be used to create neural networks that “compute” functions without needing a learning process at all.
It is possible to create random connections yes. When you do this:
Nengo will create a connection between all of the neurons in ens1 and all of the neurons in ens2. You can set the <weight matrix> to a bunch of random values to create random connections. If you set any element to 0, it will effectively mean that the respective neurons are not connected. I should note that Nengo operates on the “ensemble” (a group of neuron) level, rather than on the individual neuron level. This is done to increase the efficiency of the computation of the neural simulation.
Yes you can. There are multiple ways to do it. You can define a function which references an object that you can change the value of. Or, the way I like to do it is to define a class where all of the data can be stored and manipulated. You can then pass a method of the class as the node’s input function, and modify the data (i.e., modify the class information) without touching the Nengo model at all:
class InputFunc:
def __init__(self, ...):
self.data = ...
def step(t):
return self.data[...]
my_input = InputFunc()
with nengo.Network() as model:
inp = nengo.Node(my_input.step)
....
# Run first simulation
with nengo.Simulator(model) as sim:
sim.run(1)
# Modify data
my_input.data = ....
# Run second simulation
with nengo.Simulator(model) as sim:
sim.run(1)
I sort of touch on the reason for this earlier. In Nengo (or rather, in the NEF), the thought paradigm is that with the appropriate set of decoding weights, one can take a spike train, filter it through a synapse, and apply the decoding weights to get out a real-valued time varying signal that represents what your network is supposed to produce / calculate. In this way, the way information is encoded in Nengo straddles the line between spike-pattern coding and a rate-based coding where it is both, and neither at the same time (it’s very confusing… i know… it takes a while to get your head wrapped around this concept). For this reason, Nengo probes can be configured to apply a set of decoder weights (this is done by default on certain objects) and a synapse (to filter the spike data). By default, when you probe a .neurons object, Nengo will not apply any decoding weights, nor will it add a synapse, so you will get the raw spikes.
That’s really up to you. The default synapse is an exponential synapse with a \tau value in Nengo is 0.005s, and this is based on the (average-ish) synaptic time constant of the AMPA neurotransmitter. You can definitely change the synaptic value (and indeed even the synapse type – e.g. to an alpha synapse) to whatever your model requires. As an example, the Nengo integrator example uses a 0.1s exponential synapse. This value was chosen to be in line with the longer time constants of the NMDA neurotransmitter. My old research lab has a table of neurotransmitter time constants that serve as a decent reference for values.
That is correct. Weights can also be set manually.
This forum post has a description and a link to the Nengo documentation on connections. These two sources provide a good explanation of the different types of connections you can create with Nengo objects.
But to briefly answer your question:
Connecting to an ensemble means that the signal gets passed through (multiplied with) the neurons’ encoders (this is described in the NEF algorithm) before being used to compute the neurons’ activity function. Connecting to a .neurons object means that the connection is being made to the neurons directly, bypassing the neural encoders.
This answer has a bit more nuance to it, and it depends entirely on what object the connection is connected to. If the connection is to an ensemble object, then both the transform and the function serve to inform the connection weight solver with information on how to solve for the connection weights. I go into detail about how this works in this forum post. To quickly summarize that post, the transform parameter instructs the solver to solve for decoders that perform a scalar multiple. On the other hand, the decoders serve as “one-half” of the full connection weight matrix of a Nengo connection. The “other-half” are the encoders in the post population. If you do a matrix multiplication of the decoders and the encoders, you’ll get the full connection weight matrix.
If you are connecting to a .neurons object, however, the transform parameter gets treated like the input weight matrix to the post population. If both the pre and post objects are .neurons, then the transform parameter essentially becomes the connection weight matrix.
Connecting to a .neurons object means that the connection is being made to the neurons directly, bypassing the neural encoders.
Does it mean that it also bypass decoders ? So if I have recurrent connections and I want that neurons transmit information as spikes between them I should use .neurons right ?
I can’t thank you enough for your help and patience, I learned a lot !!
I’m still a little unclear what you mean by “transmit information as spikes”. Although there are some abstractions, spiking neural networks in Nengo try to emulate the same processes found in biology. Biologically, at the most simplistic level, input current is injected into a neuron, which causes a neuron to spike. This spike then travels down the axon to a synapse, which causes a release of neurotransmitters, which in turn causes an influx of current (PSC) into the dendrite, and then the whole process repeats itself. To summarize:
input current → neuron → spike → synapse → input current
Nengo does this as well, with a few minor changes. First, instead of operating on individual neurons, Nengo groups them into ensembles (each neuron is still simulated, it’s just that the input and outputs are grouped up). Second, each synapse has a weight associated with it. This is the “connection weight”. So, in essence:
input current → neurons → spikes → synapse → synapse weight → input current
What Nengo does that is special is another layer of abstraction based on the NEF algorithm I mentioned before. You’ll need to watch the Youtube videos I linked to get a better understanding of the NEF, but one of the effects is that the connection weights can be factored in order to make it “compute” functions. The factored components of the connection weights are the encoders and decoders.
input current → neurons → spikes → synapse → decoders → encoders → input current
There are several important things to note about the NEF. First, it operates on the ensemble level, because a larger amount of neurons means a better representation of the function you want to compute. Second, in the NEF (and in Nengo), the decoders are associated with the connection itself, and the encoders are associated with the “post” population. If you want the full connection weight matrix between two populations, you simply to a matrix multiplication of the respective decoders and encoders.
All of the above is to say that in Nengo, whether or not you are connected to the ensembles or to the .neurons attribute of the ensembles, information is still transmitted through spikes. Whether or not you connect to ensembles or neurons depends on the design of your network. If the network you are making have connections where you can define the function you want to compute, then you’ll want to do the connections from ensembles. If, however, the connection weights are random and learned (or cannot otherwise be factored into encoders and decoders), then you’ll want to connect to the neurons.
I think you mean to ask “what does it mean to bypass the encoders”. In Nengo, if you connect to a .neurons object, the connection weights do not include the multiplication with the encoders of the “post” population. Thus, they are “bypassed”.
I think you mean to ask “what does it mean to bypass the encoders”. In Nengo, if you connect to a .neurons object, the connection weights do not include the multiplication with the encoders of the “post” population. Thus, they are “bypassed”.
Are intercepts used in encoding ? Because they seems to modify the behavior of my model even if I have direct connections only. Or are encoders converting values from dimensional space to vector space, so values are in the tuning curve range ? By the way, why my neurons fire if I have no input spikes ? This is why I tried to set intercepts to 0.
Also, if I understood correctly, in direct connections, spikes are filtered through synapses, multiplied by weights (“decoders”), and the output value is the direct input of the neuron ? Is it the value accessible when probing a connection variable ? Because depending on my weight initialization (randomized and fixed), probed values could be very high (> 1000) or very low (< 1). This affects results and I don’t understand how this value can be fed to the neuron when it is very high.
Finally, do synapses add delay or do they modify values ? When adding a not None synapse in my Probe, values are decaying but I do not observe any delay.
No, the intercepts determine when the neurons start spiking in relation to the value of the input current being provided to the neuron.
You sort of have the right idea, but some incorrect terminology. We tend to refer to the “abstract” domain (i.e., the domain where everything is real-valued, possibly multi-dimensional and interpretable by the user) as the “vector space” and the domain in which the neurons operate as “neuron space” or “current space”. You are correct in the understanding that encoders serve to convert values from the vector space into neuron space.
The other point of clarification is about tuning curves. Tuning curves display the mapping between inputs in vector space, and the activity of the neuron (as a firing rate). Because of this, tuning curves can be single dimensional, or multi-dimensional (as evidenced in this example). There is a tuning curve analogue in neuron space, and that’s the neuron response curve. Unlike tuning curves, response curves are always one-dimensional. Additionally, where tuning curves can be oriented in any direction (for 1D, in the positive or negative X direction; for 2D, pointing in any direction in a circle, etc.), response curves only point in the positive X direction. That is to say, for tuning curves, the firing rate of the neurons get higher in the positive X direction, and you will not see any neurons that have firing rates that increase in the negative X direction.
There may be several reasons why this can occur, and since I do not have your code to analyze, I’ll describe the most probably reason why this would occur. I assume you are speaking of the case where the input value (in vector space) to your neuron is a negative number, and you’ve set the neuron intercept to 0, but the neuron is still firing? If this is the case, it’s because the neuron’s encoders are negative as well.
As was discussed above, neurons have two properties: encoders and intercepts. The encoders determine which direction the neuron is responsive in, and the intercepts determine how far along said “direction” does the neuron start to spike. Suppose your input to the neuron is negative, and so is your encoder. The negative encoder means that the neuron will be more active the more negative the input gets, so if your input is below 0, the neuron will still fire. It’s a lot clearer if you convert everything into neuron space. In neurons space, the negative X value and the negative encoder cancel each other out (because they are multiplied with each other), so you are actually injecting positive current into the neuron, and that’s why it spikes. To stop the neurons from firing, you’ll need to ensure that the intercepts are 0, and the encoders are positive.
If you are doing something like this:
nengo.Connection(ens1, ens2.neurons)
Then yes, this would be the case. However, if your “direct” connection comes from a neurons object, and terminates at a neurons object, like so:
The data p_conn records would be the filtered spikes (multiplied by the decoder) for each neuron in the connection’s source ensemble. As to why the probed values are high or low, it depends on what your weight matrix is. In Nengo spikes are represented as a value that exists for 1 timestep and has a magnitude of 1/dt (where dt = 0.001s by default). If you let Nengo solve for the weight matrix for you, it will take this into account when doing so, such that the decoded output of the ensemble is in the correct range. If you are generating the weight matrix yourself, you’ll need to ensure that the weights are not so large that they “blow out” the values going to the post population.
With regards to the post populations, it is entirely possible to feed it values that are way too high. When this is the case, the neurons saturate (fire at some maximum rate) and increasing the input value further will not have any effect on the firing rate of the neuron (note: this is only for the LIF neuron).
The default synapse in Nengo is an exponential synapse. If you are looking at spikes, an exponential synapse applied to a spike will make the output jump to some value, then slowly decay back down to 0. However, when applied to a continuous signal, an exponential synapse has the same effect as applying a low-pass filter to the signal. Some people consider a low-pass synapse as a “delay”, especially if you consider the application of a low-pass filter on a step signal. I’m not entirely sure what you mean by “delay”, so you’ll have to clarify.