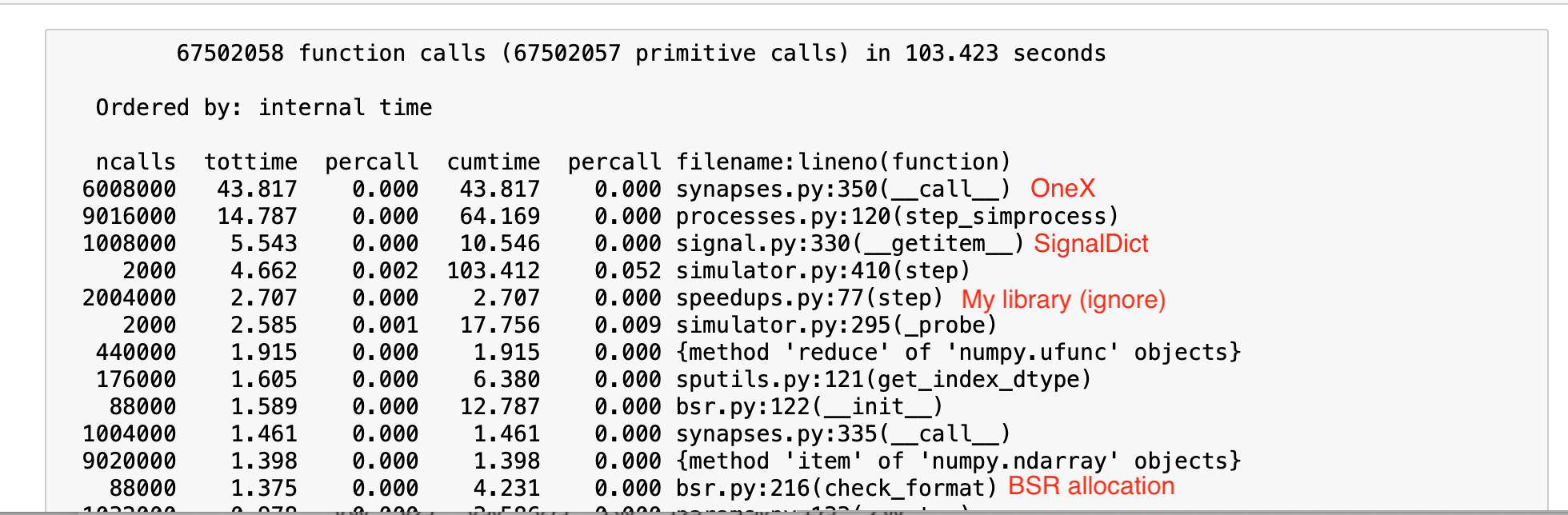
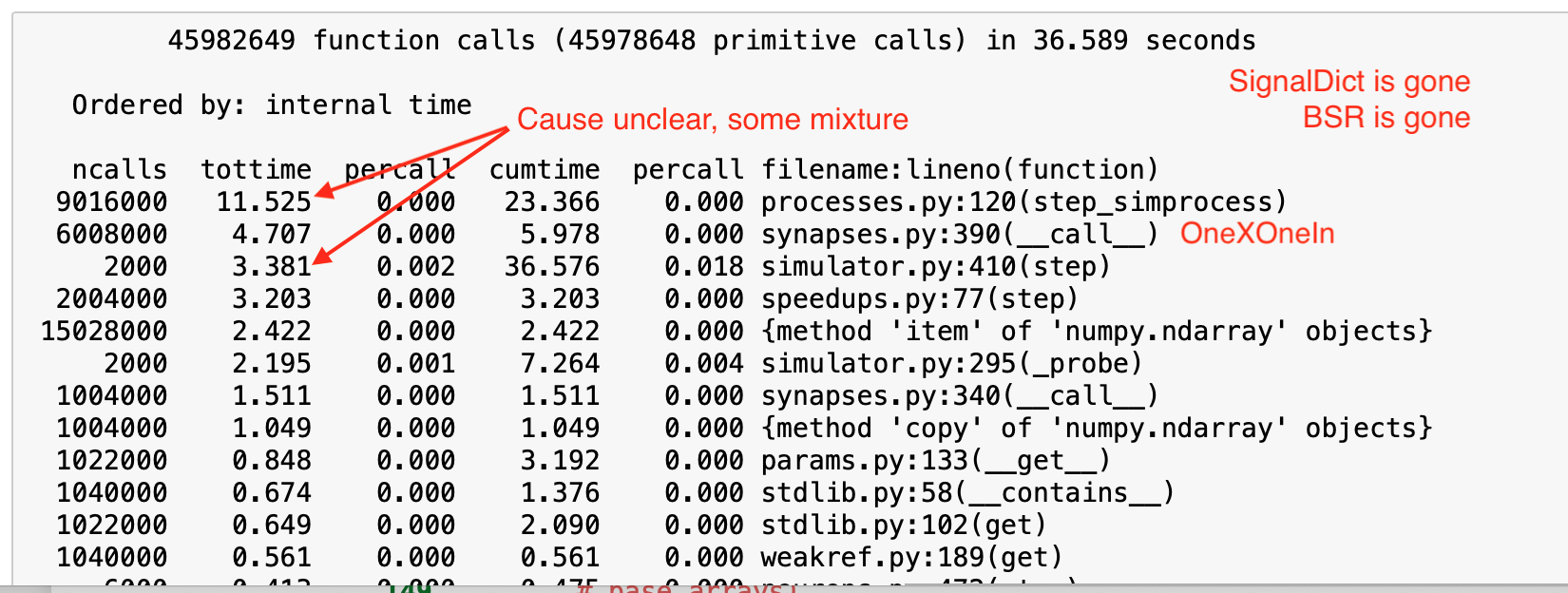
This isn’t exactly a HPC topic; I am doing performance optimizations on my 4-core macbook. After some profiling, I found some bottlenecks in the core. The fixes are relatively simple. They reduced simulation time by about 30%.
The branch is at https://github.com/atait/nengo/tree/optimizations-core
I wanted to ask for feedback before making an issue or PR because I have a very limited understanding of all of the use cases and inner workings of Nengo. Only one nengo-bones test failed (pickling, see below), but those might not perfectly cover everyone relying on Nengo core.
Also, I just benchmarked off of one case, but these should be individually benchmarked before going forward to see if it’s worth it. The test case was a network with about 10k Ensembles of 30 neurons apiece and about 8 Connections projecting to other Ensembles.
Stop initializing BSR matrix on every step call
This probably only shows up when you have lots of small Ensembles.

Store SignalDict misses
When a requested key is not in the dict, SignalDict can fall back and allocate a new ndarray. Chances are that whatever requested that key will request it again, so we keep it around
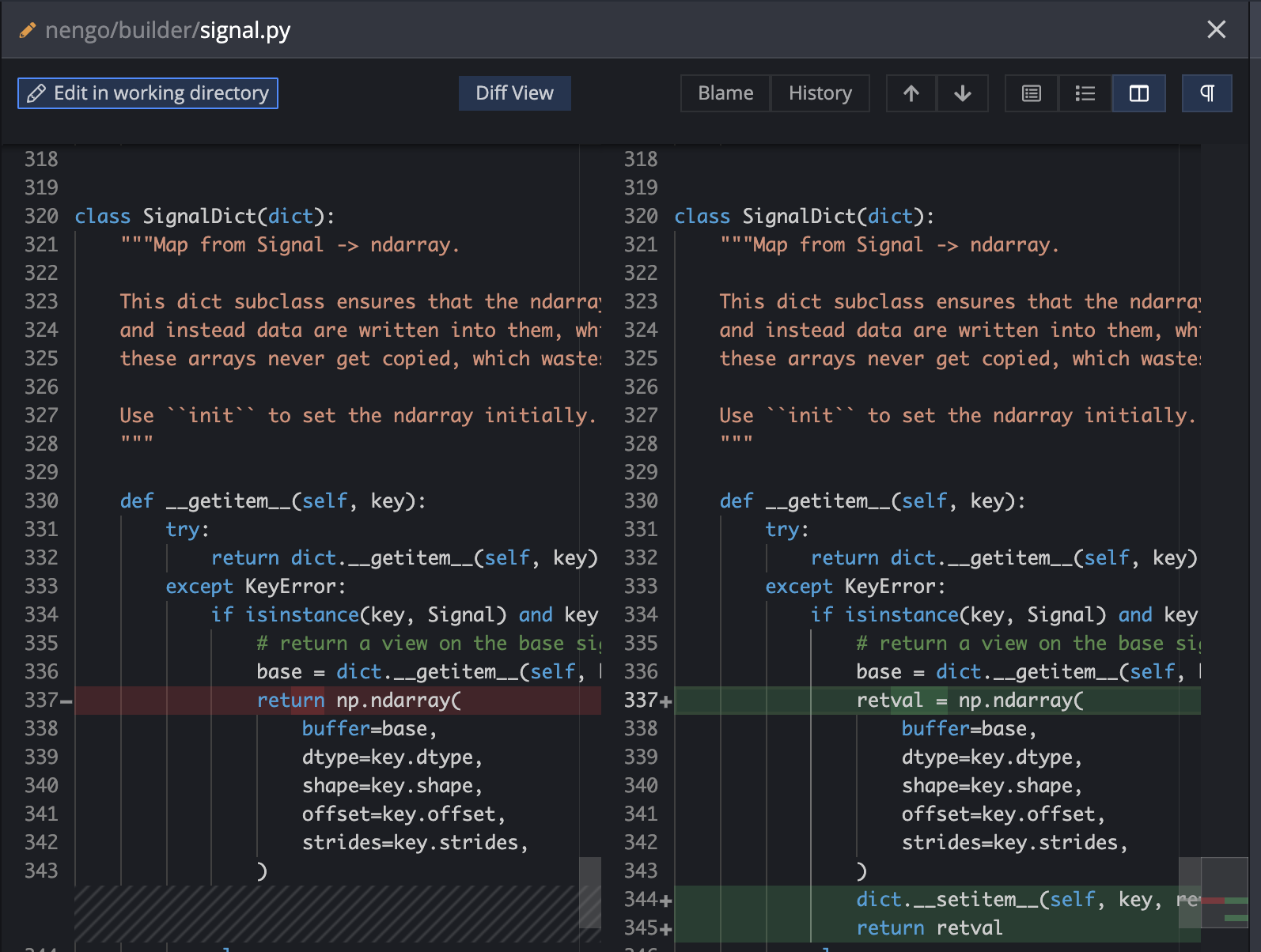
Potential side effect: if the calling entity is relying on getting a freshly allocated ndarray every time. That would be violating the typical expectations of a dictionary, but I suppose it could happen.
Circumvent np.clip from numpy 1.17
It introduced significant slow down. https://github.com/numpy/numpy/issues/14281. The rest of Nengo is very good about numpy dtype handling, so it can be replaced with the underlying ufunc.
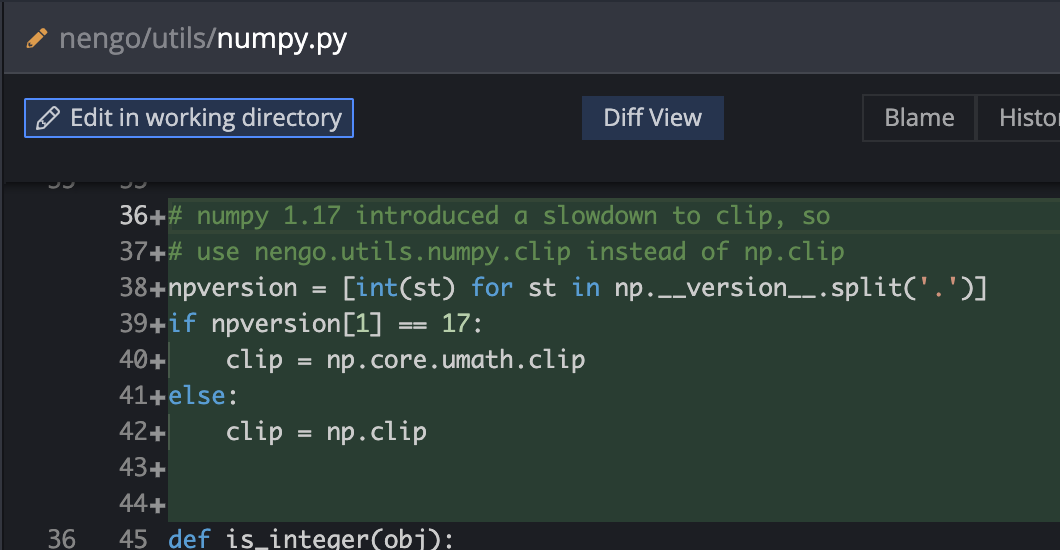
Potential issue: if user code is feeding in mismatched dtypes, they might find their way to the ufunc and break it.
For example,

Also, replaced all some_ndarray.clip(a, b) with clip(some_ndarray, a, b) and all clip(some_ndarray, a, None) with np.minimum(some_ndarray, a). This is safe for all user code.
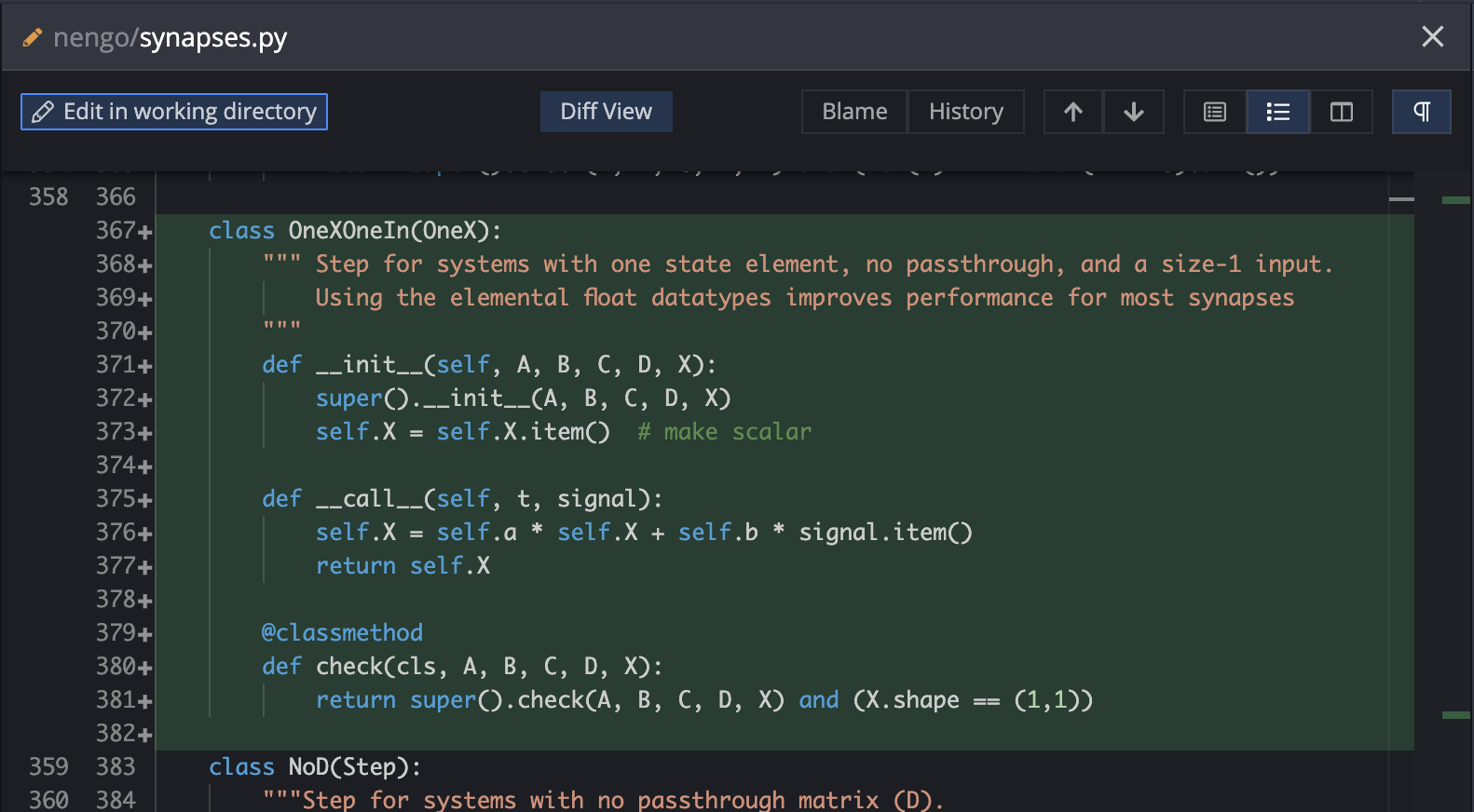
Size 1 LinearFilter using builtin float
Builtin floats outperform single-element numpy arrays. This type of filter is a workhorse in some networks. OneXOneIn, like its sister classes, checks the state-space filter parameters to determine when it is applicable.
Numba-fy the OneX LinearFilter (probably nengo-extras)
Numba can give you about an order-of-magnitude speedup on numpy code. Under the hood, it uses compiler options, cache exploits, threading, Intel-specific CPU features (if present), etc. With sufficient motivation, one can also tailor its compilation to NVIDIA cards.
This is exactly what you need to do to fully use a modern computer. The whole point of numba is to make those intricacies as pythonic as possible; however, JIT code must surrender some key things.
- does not pickle natively (
test_pickle_simfailed; workaround is possible) - does not handle 16 bit floats (
test_dtype[16]passes using a workaround) - impossible to debug, but it’s easy to turn off the JIT decorator for this
- exhaustive testing acquires either a hardware-dependent aspect or a deep trust of the numba developers.
The OneX filter is the basis of the Lowpass filter, and, in turn, the most common Synapse. It’s a major workhorse, and it is pretty straightforward, so potential for a bug is low.
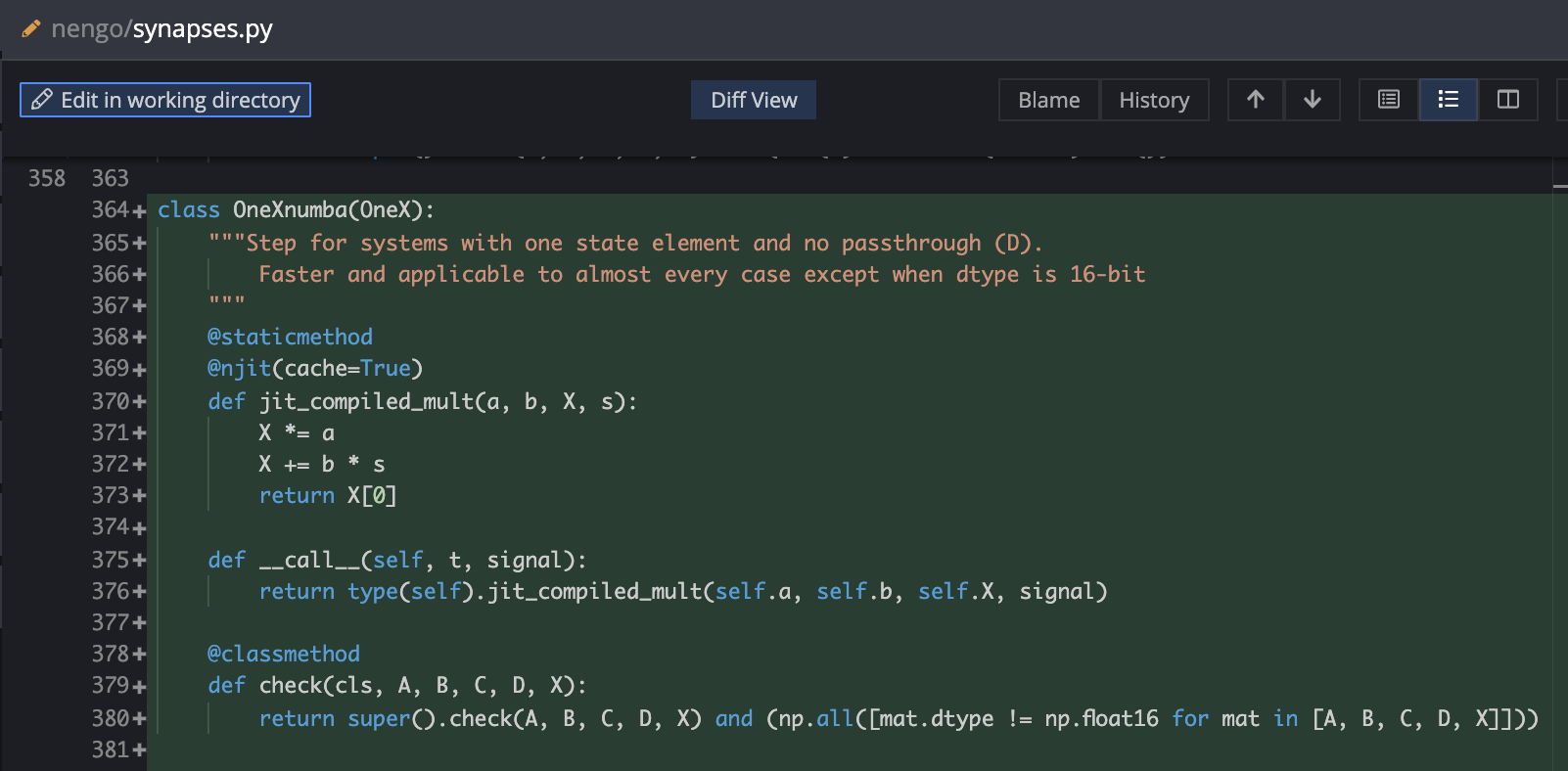
Perhaps a bigger downside is the additional dependency on numba, so I perceive this one as a component of nengo-extras, if anything.