I am trying to implement unsupervised learning in a model using memristors as synapses by adapting the BCM learning rule. I have already successfully done the same for supervised learning by adapting PES.
I think I have the needed understanding of the theory down but I wonder if my model may not be working because of some strange effects I can see in Nengo; to be precise, my post population seems to be firing before it should.
My ensembles are set up as such:
nengo.Connection( inp, pre )
nengo.Connection( pre.neurons, learn[ :pre_nrn ], synapse=0.005 )
nengo.Connection( post.neurons, learn[ pre_nrn: ], synapse=0.005 )
nengo.Connection( learn, post.neurons, synapse=None )
with learn being a Node() object implementing my weight calculation. As you can see, I have a synapse of tau=0.005 on both the connection from pre and post (even though it’s None in the Nengo implementation, I have to add a delay here to avoid cycles) to learn.
The full code can be found here and here.
learn implements the following learning rule:
def mBCM( self, t, x ):
input_activities = x[ :self.input_size ]
output_activities = x[ self.input_size: ]
theta = self.theta_filter.filt( output_activities )
alpha = self.learning_rate
# function \phi( a, \theta ) that is the moving threshold
update = alpha * output_activities * (output_activities - theta)
if self.logging:
self.history.append( np.sign( update ) )
self.save_state()
# squash spikes to False (0) or True (100/1000 ...) or everything is always adjusted
spiked_pre = np.array( np.rint( input_activities ), dtype=bool )
spiked_post = np.array( np.rint( output_activities ), dtype=bool )
# we only need to update the weights for the neurons that spiked so we filter
if spiked_pre.any() and spiked_post.any():
for j in np.nditer( np.where( spiked_post ) ):
for i in np.nditer( np.where( spiked_pre ) ):
self.weights[ j, i ] = self.memristors[ j, i ].pulse( update[ j ],
value="conductance",
method="same"
)
# calculate the output at this timestep
return np.dot( self.weights, input_activities )
If I’m understanding things correctly, this should mean that I will see the first neural activities from pre in mBCM() at t=0.006 (i.e., after 5 timesteps) and the first ones from post around t=0.0012.
What I’m seeing instead is the following; at t=0.005 everything is as expected:

but at
t=0.006 I instantly see that post is also firing: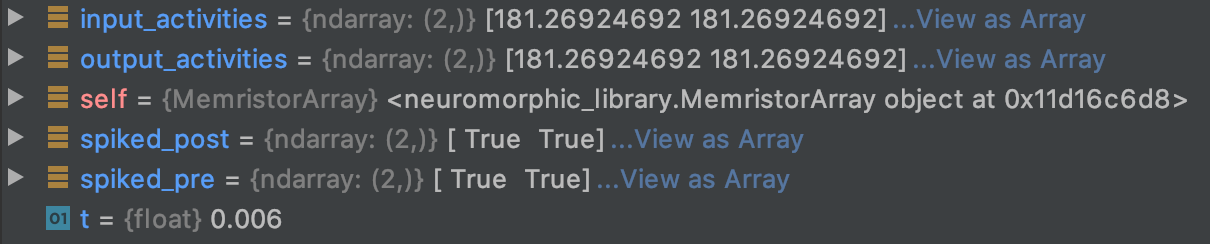
The result of applying my rule is that the post neurons are always firing, could it be connected to this phenomenon I’m seeing?
Should I be specifying some initial weights like in the tutorial?