Hi Iry, I am a new user of Nengo too, but I think I can provide some of my experience with using PES learning rule on a labelled dataset (after weeks of assistance from @xchoo). Basically I tried to make a network as follows:
"""
MNIST PES Learning
We attempt to use PES learning rule to learn the MNIST classification.
"""
import nengo
import numpy as np
from utils import preprocess
import tensorflow as tf
from nengo_extras.gui import image_display_function
from nengo_extras.data import one_hot_from_labels
from nengo_extras.vision import Gabor, Mask
# Load data
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
T_train = one_hot_from_labels(y_train)
input_size = X_train[0].reshape(-1).shape[0]
model = nengo.Network(label='mnist')
rng = np.random.RandomState(9)
with model:
vision_input = nengo.Node(lambda t: preprocess(X_train[int(t)]), label="Visual Input")
encoders = Mask((28,28)).populate(
Gabor().generate(10, (11,11), rng=rng),
rng=rng,
flatten=True
)
# Ensemble to encode MNIST images
input_ensemble = nengo.Ensemble(
n_neurons=6000,
dimensions=input_size,
radius=1
)
nengo.Connection(
vision_input, input_ensemble
)
# Ensemble to encode MNIST labels
output_ensemble = nengo.Ensemble(
n_neurons=300,
dimensions=10,
radius=5
)
conn = nengo.Connection(
input_ensemble, output_ensemble,
learning_rule_type=nengo.PES(),
transform=encoders
)
error = nengo.Ensemble(
n_neurons=300,
dimensions=10,
radius=5
)
label=nengo.Node(lambda t: T_train[int(t)], label="Digit Labels")
nengo.Connection(output_ensemble, error)
nengo.Connection(label, error, transform=-1)
nengo.Connection(error, conn.learning_rule)
# Input image display (for nengo_gui)
image_shape = (1, 28, 28)
display_func = image_display_function(image_shape, offset=1, scale=128)
display_node = nengo.Node(display_func, size_in=vision_input.size_out)
nengo.Connection(vision_input, display_node, synapse=None)
inp_ens_disp = nengo.Node(display_func, size_in=784)
nengo.Connection(input_ensemble, inp_ens_disp, synapse=0.1)
If you are more comfortable with gui, here is a screenshot of what it looks like in Nengo GUI simulation:
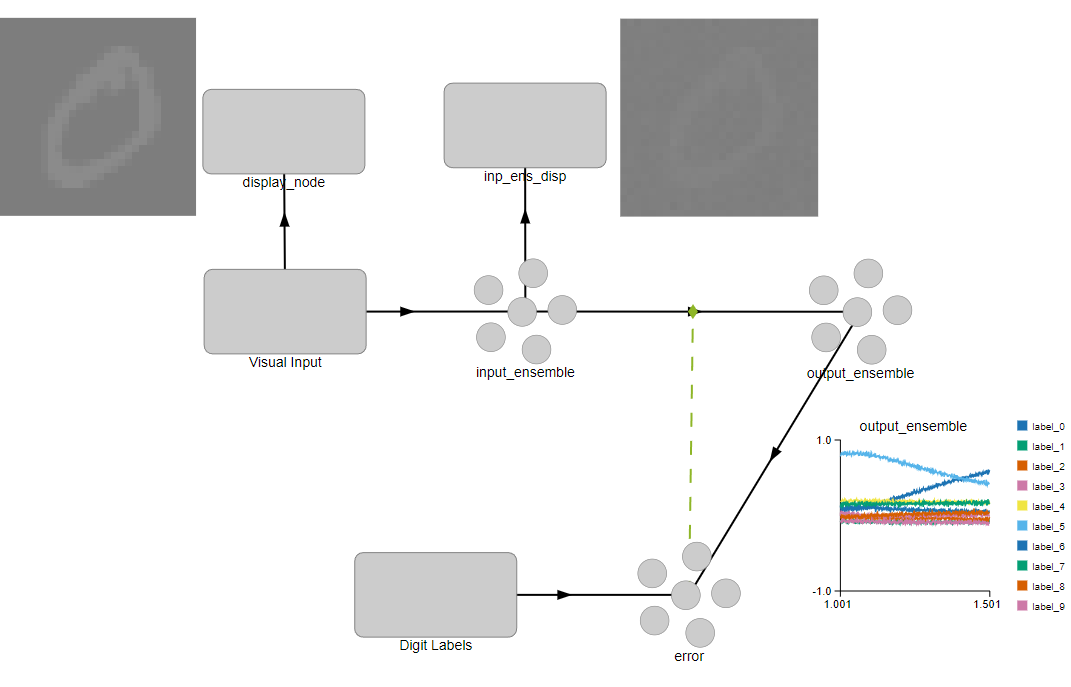
A few observations I made about the PES learning rule:
- PES is a local learning rule. Therefore, I can only make it learn the connection between 2 neuron ensemble. If I have a deep network, I won’t know how to “split” the error to assign to the different connection weights at different layers (known as the credit assignment problem, which backpropagation solved but we are lacking something like this in SNN).
- PES seems to overcompensate for every new input. If I run the simulation for 100s and then inhibits the error signal to stop the learning, the weights seem to be only optimized for the last seen digit. You can see the behavior in this simulation:
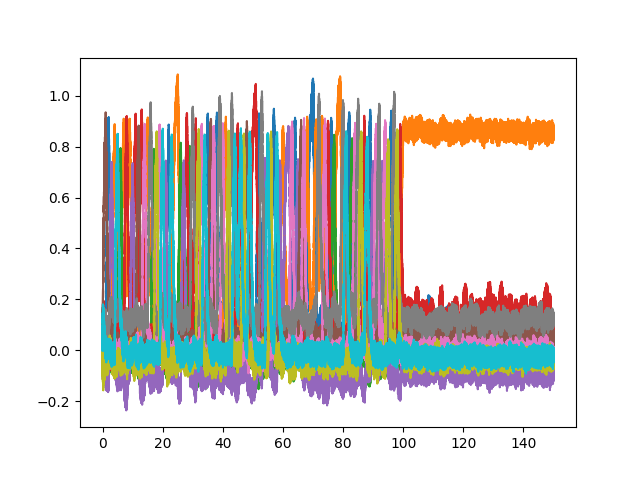
So far I am not sure if there is anything wrong with what I am doing, since most examples on Nengo websites are using a scalar error signal, while I am using a vector error that adjusts every dimension of the one hot encoded label. Maybe we can further discuss how to make this work, but just putting it out there that this is a potential pitfall. - Since PES learning rule works as an online learning rule, we can’t really leverage the efficiency of minibatches that we are so used to in backpropagation. For MNIST, we have 60,000 training images. If we show each image for 1s it will take 16.67hrs to run through the entire dataset once. I think it might make more sense to learn a representation with minibatch bp first before using PES to adjust for online OOD samples.