Hi, when I was looking at the example, I found that the given PES learning rules don’t seem to use the target. I remember PES should be a supervised learning method. But from the examples given it is more like unsupervised learning.
I am planning to use PES learning rules to learn on a dataset. If it’s supervised learning, can you tell me where should I put targets in the network construction? I didn’t find a similar example. I would be grateful if you could help me.
Hi Ruoyuan. Which example are you referring to? In our PES learning examples, you should see at some point there’s a connection made into the .learning_rule attribute of another connection. For example, in the learning to square the input example, the line nengo.Connection(error, conn.learning_rule) connects the ensemble that’s tracking the error into conn.learning_rule, where conn is the connection that the learning rule is applied to. Connecting into the .learning_rule attribute in this way is how we provide the error signal to the PES learning rule. The error ensemble here is representing the difference between the actual output of the post Ensemble (A_squared), and our “target” output (which is computed in this connection: nengo.Connection(A, error, function=lambda x: x**2, transform=-1)). This error signal is what makes PES a supervised learning rule.
In your own network, you want to compute that error signal by taking the difference between the outputs and the targets, and connect that into the .learning_rule attribute on your learning connection. Make sure to compute the error as actual_output - target_output, as if you compute the difference the other way around then the learning will go in the wrong direction.
Thank you so much for your help! As a newbie I have a few more questions.
1, can I use nengo_dl.simulator to simulate a neural network with a learning rule of PES? When I was looking at the documentation I saw that nengo_dl has an effect on the elements learned online.
2, the error is obtained by actual- target, but in my dataset target is a series of labels. I don’t have any idea how to represent post- targets at the moment.
Yes you can! But, it should be noted that the PES learning rule is an online learning rule (i.e., it modifies the connection weights only when the simulation is running). Whereas the sim.fit function is an offline learning rule. Because of this, in NengoDL, when you call sim.fit it does not run any of the PES learning rules, and when you run the simulation (to use PES), it does not call the sim.fit training function.
Right… This is a very problem dependent question. Typically, datasets that just contain labels are better suited for offline training methods (using backprop, for example). It may be possible to use the PES to learn your problem, but I do not have much experience with that, so my advice is limited.
Hi, I have a similar question to him and I hope you can answer it. I want to train and classify using bcm learning rule in nengo_dl.simulator, I think sim.fit is necessary, is there any way to make my idea happen, or if sim.fit is not necessary, is there any way to train using bcm rules in nengo_dl.simulator and then achieving classification?
Any help is appreciated.
Hi Iry, I am a new user of Nengo too, but I think I can provide some of my experience with using PES learning rule on a labelled dataset (after weeks of assistance from @xchoo). Basically I tried to make a network as follows:
"""
MNIST PES Learning
We attempt to use PES learning rule to learn the MNIST classification.
"""
import nengo
import numpy as np
from utils import preprocess
import tensorflow as tf
from nengo_extras.gui import image_display_function
from nengo_extras.data import one_hot_from_labels
from nengo_extras.vision import Gabor, Mask
# Load data
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
T_train = one_hot_from_labels(y_train)
input_size = X_train[0].reshape(-1).shape[0]
model = nengo.Network(label='mnist')
rng = np.random.RandomState(9)
with model:
vision_input = nengo.Node(lambda t: preprocess(X_train[int(t)]), label="Visual Input")
encoders = Mask((28,28)).populate(
Gabor().generate(10, (11,11), rng=rng),
rng=rng,
flatten=True
)
# Ensemble to encode MNIST images
input_ensemble = nengo.Ensemble(
n_neurons=6000,
dimensions=input_size,
radius=1
)
nengo.Connection(
vision_input, input_ensemble
)
# Ensemble to encode MNIST labels
output_ensemble = nengo.Ensemble(
n_neurons=300,
dimensions=10,
radius=5
)
conn = nengo.Connection(
input_ensemble, output_ensemble,
learning_rule_type=nengo.PES(),
transform=encoders
)
error = nengo.Ensemble(
n_neurons=300,
dimensions=10,
radius=5
)
label=nengo.Node(lambda t: T_train[int(t)], label="Digit Labels")
nengo.Connection(output_ensemble, error)
nengo.Connection(label, error, transform=-1)
nengo.Connection(error, conn.learning_rule)
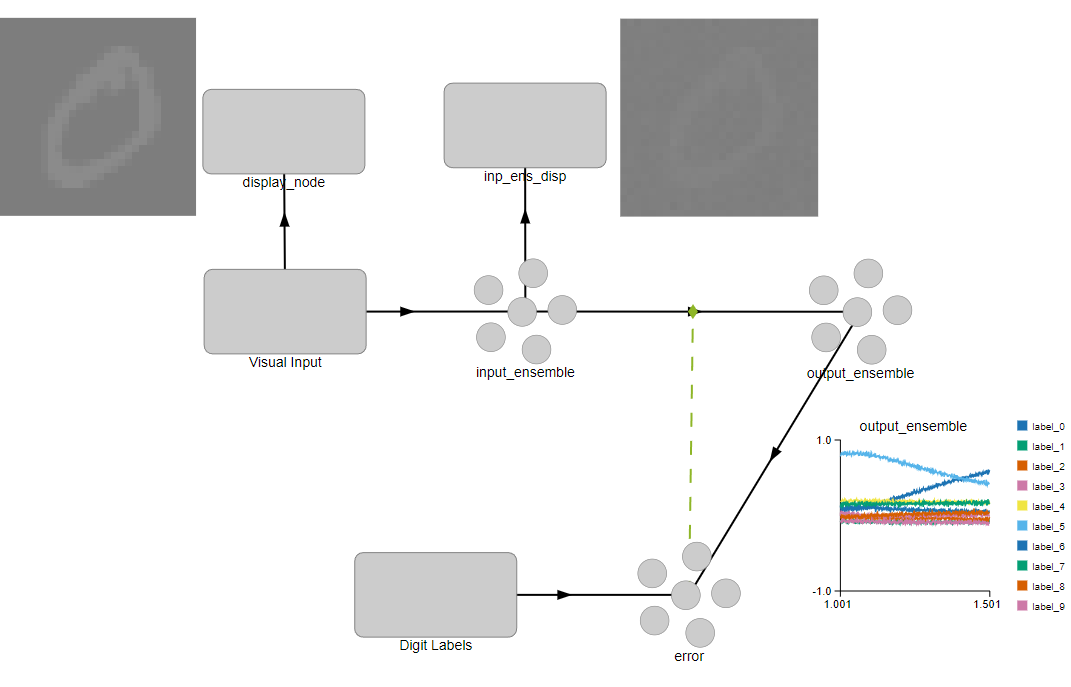
# Input image display (for nengo_gui)
image_shape = (1, 28, 28)
display_func = image_display_function(image_shape, offset=1, scale=128)
display_node = nengo.Node(display_func, size_in=vision_input.size_out)
nengo.Connection(vision_input, display_node, synapse=None)
inp_ens_disp = nengo.Node(display_func, size_in=784)
nengo.Connection(input_ensemble, inp_ens_disp, synapse=0.1)
If you are more comfortable with gui, here is a screenshot of what it looks like in Nengo GUI simulation:
A few observations I made about the PES learning rule:
PES is a local learning rule. Therefore, I can only make it learn the connection between 2 neuron ensemble. If I have a deep network, I won’t know how to “split” the error to assign to the different connection weights at different layers (known as the credit assignment problem, which backpropagation solved but we are lacking something like this in SNN).
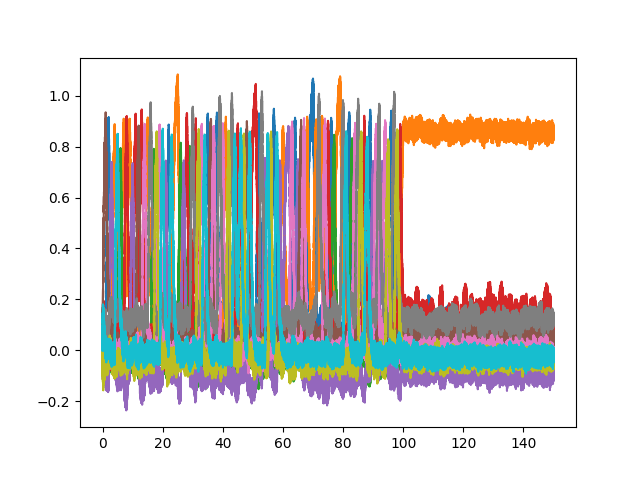
PES seems to overcompensate for every new input. If I run the simulation for 100s and then inhibits the error signal to stop the learning, the weights seem to be only optimized for the last seen digit. You can see the behavior in this simulation:
So far I am not sure if there is anything wrong with what I am doing, since most examples on Nengo websites are using a scalar error signal, while I am using a vector error that adjusts every dimension of the one hot encoded label. Maybe we can further discuss how to make this work, but just putting it out there that this is a potential pitfall.
Since PES learning rule works as an online learning rule, we can’t really leverage the efficiency of minibatches that we are so used to in backpropagation. For MNIST, we have 60,000 training images. If we show each image for 1s it will take 16.67hrs to run through the entire dataset once. I think it might make more sense to learn a representation with minibatch bp first before using PES to adjust for online OOD samples.
The BCM learning rule can technically be trained using the nengo_dl.Simulator, but, I have to once again make the distinction between online and offline training. The BCM learning rule, just like the PES learning rule, is an online learning rule. Whereas the sim.fit call is an offline learning rule. As I mentioned before, both do not run at the same time.
As to whether sim.fit is necessary with the BCM rule? I’m not clear on whether it is or isn’t. If you use the BCM rule, you will be modifying the connection weights to optimize a certain function (whatever function the BCM rule is optimizing). But, if you then use sim.fit after this process, you take whatever the BCM rule has learned, and then “override” it with whatever sim.fit is doing. At best, you are just seeding the sim.fit function with the output of the BCM rule…
As to whether you can train using the BCM rule, and then do classification on it? Yeah… that should be possible. I think you can run your network with the BCM rule for some amount of time, then save the weights, and create a “static” version of your network to then run the classification on it.