Hope all’s well! I have a question regarding the use of SPA for classifying numeric vectors into discrete class labels. The task I am trying to achieve is to classify EMG signals into one of two gestures (GEST1 and GEST2), where a network vocabulary contains the reference gesture that the network can use to compare an input signal against.
The input data which is fed to the network is structured as windows of semantic pointer vectors and it is passed to the network using the nengo_dl batch processing functionality. The semantic pointers were created using the nengo_spa.SemanticPointer() constructor.
My thinking was that if I create semantic pointer vectors which are encoding the EMG signal, that I could use the action selection mechanism provided by SPA to determine what the gesture is but I am encountering the problem where the network is having difficulty differentiating between the input semantic pointers.
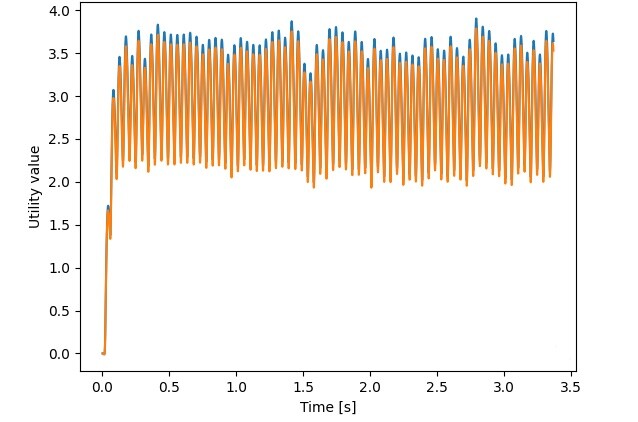
I’ve attached a screenshot below showing the behaviour of the network for trying to classify between the 2 gestures, where the orange and blue lines represent the utility values calculated by the network for each window of input fed into the network.
The code for creating the network vocabulary is pasted below for reference:
The code for my network is pasted below for reference:
model = spa.Network(seed=seed, vocabs=[network_vocab])
with model:
"""
Network definition
"""
input_node = nengo.Node(output=np.zeros(dimensions))
input_sp = spa.SemanticPointer(input_node.output)
input_transcode = spa.Transcode(input_sp, output_vocab=network_vocab)
# Specify the modules to be used
cortex = spa.State(network_vocab, dimensions)
input_transcode >> cortex
output = spa.State(network_vocab, dimensions)
"""
Main network code
"""
# Specify the action mapping
with spa.ActionSelection() as action_sel:
spa.ifmax("Gesture 1 Selection", spa.dot(cortex, network_vocab['GEST1']), spa.sym.GEST1 >> cortex)
spa.ifmax("Gesture 2 Selection", spa.dot(cortex, network_vocab['GEST2']), spa.sym.GEST2 >> cortex)
I’m still quite new to SPA so apologies if this is a really trivial task. But from this, I have some questions:
Is there a preferred method of creating semantic pointers for numeric value vectors (for example, EMG data) or is the use of nengo_spa.SemanticPointer() ok to use?
When providing data for the action selection mechanism to use, do these data values have to be within a desired range? As I read on another forum post that the basal ganglia network prefers data within the range 0.3 - 1 and the documentation of nengo_spa.action_selection says that it implements a basal ganglia behind the scenes
Lastly, do you have any tips/advice for improving differentiation between signals using SPA? Possibly some parameter that should be tweaked or whether data should be formatted in such a way
The nengo_spa.Vocabulary.add() function allows you to provide either a nengo_spa.SemanticPointer object, or an “array-like” (e.g., Python list, Numpy array, etc.) object as the second parameter, so both are good to use. If your question is instead whether using the .add function is the way to insert semantic pointers of pre-specified vectors into a vocabulary, then the answer is yes!
The BG network (as with many other SPA networks) typically assume that the incoming semantic pointers have a vector magnitude of 1. While the BG network can tolerate inputs with a slightly larger magnitude (up to about 1.2), you will get better performance if you keep the input vector magnitudes within the 0.3 - 1 range.
This question is rather open-ended and I have a few comments, so I’ll organize them into 4 sections: vector magnitudes, semantic pointer generation, alternative approaches, and general code comments.
Vector Magnitudes
I sort of alluded to this when discussing the inputs to the BG network. In NengoSPA, there is an implicit assumption that the semantic pointers (or vectors) used in the model have an expected vector magnitude of about 1. There are several reasons for why this is the case:
With SPA models, one of the vector operations needed is the ability to compute the similarity of an input vector with a reference vector (this vector can be static or a dynamic vector, like the input). Because of it’s simplicity to implement, the dot product (a.k.a., inner product) is used in many of the built-in SPA networks (the BG included). Some SPA models do use other similarity measures, but I won’t discuss that here. For the dot product to serve as a good standard to compare different vectors, it must have a consistent frame of reference. In the SPA system, this frame of reference is to ensure that the reference vector must have a magnitude of 1. There is also an implicit understanding that the dot product will only produce meaningful results when the input vector also has a magnitude of 1 (although, we tend to bend this “rule” quite a lot… but we do so with the understanding of how the dot product works).
Another reason for the unit vector magnitude is the way the neural ensembles in Nengo are optimized (although, this doesn’t quite hold true for very large vector dimensions). In Nengo, the representational range of an ensemble is optimized to be within a unit hypersphere (i.e., the high dimensional sphere with a magnitude of one). That is say, the ensembles are created so that they are good at reproducing vectors within the unit hypersphere, and doesn’t bother about anything outside of it. Thus, vectors that serve as inputs to these ensembles should also be of maximum unit length, to keep within this optimization. Note that Nengo ensembles have a radius parameter that can modify the “size” of the hypersphere.
Semantic Pointer Generation
One concern I have with your current approach to using the EMG signal directly as a semantic pointer is the way that limits the possible representational space of the semantic pointers generated with this method. I assume that the EMG data is strictly positive (i.e., each vector element is never < 0), and this poses a problem. To demonstrate, in 1D, if your vector elements are always positive, it halves your representational space. In 2D, it quarters your representation space (i.e., if both x and y have to be >= 0). In 3D, this space is 1/8th of the total available volume of the sphere. I believe, generally for a semantic pointer of D dimensions, limiting your vector elements to always be positive would mean you’d only utilize \frac{1}{2^D} of the total representational space. By enforcing this artificial restriction, you generate vectors that will be very similar to each other regardless of how many dimensions the semantic pointer is (generally, the higher the dimensionality, the less likely two semantic pointers are similar to each other). Another concern with using the EMG signal directly is that it probably won’t adhere to the vector magnitude assumptions discussed above.
There are ways to address these issues though. Consider for example the following vector generation code:
This generates vectors that are similar to each other, and the vector magnitudes are definitely not 1.
To “fix” this vector generation, we can apply a scale and offset to the vectors (to shift the vector elements to include both positive and negative values), followed by a vector normalization:
The code does work, but there is a bit of redundancy in your code. The spa.Transcode module functions very much like a nengo.Node in the way that it can accept a Python function as the first parameter. If you do so, it will use the output of this function to drive the rest of the model. As an example, you can do this:
with model:
def input_func(t):
if t < 0.5:
return gesture1_ref_window
else:
return gesture2_ref_window
input_transcode = spa.Transcode(input_func, output_vocab=network_vocab)
With the code above, the output value of input_transcode will be the gesture1_ref_window for the first 0.5s of the simulation, and then gesture2_ref_window after that. You can read more about the spa.Transcode function here!
General Code Comments – Probes
You didn’t include any of the probes in your code, but from your graph, I presume your probe code looks something like this?
pout = nengo.Probe(output.output)
I should note that by default, Nengo probes don’t apply a synapse (i.e., a filter) to the data. This makes probed outputs of ensembles very noisy. Generally, I stick a 0.01s synaptic filter on probes to smooth this spikiness out:
pout = nengo.Probe(output.output, synapse=0.01)
I also noticed that your action selection rule set was directing the output to cortex:
I’m not sure if this was intentional, because having a rule that gets a utility value from cortex, then feeds a value back into cortex can cause unintentional feedback loops (and value flip-flopping). This may also be the cause of the spiky output data. For my testing network, I redirected the semantic pointers to output instead:
The problem you are trying to solve (at least, the implementation your network implements) is a classification problem. Generally, it is better to use a deep-learning (DL) or machine-learning (ML) network to learn these classifications rather than to use the BG network to do it. You can also use these ML classification networks to map the EMG signals onto semantic pointers as well. This then makes processing information within the SPA model easier since the NengoSPA-generate semantic pointers adhere to all of the assumptions made (i.e., magnitude, vector value distribution, etc.). This approach was done in the Spaun model where a classifier network is used to classify visual inputs, which are then mapped onto semantic pointers:
If you don’t want to go all the way to implement a DL network to do the classification, the built-in NengoSPA associative memory network can also be used to do classification. It may not be as good as a DL network (since it uses dot products to calculate similarity, so you’ll need to ensure the input vectors are normalized), but it is simpler than a full BG network, and will be able to classify inputs that are similar to each other (more so than the BG). To configure the associative memory (AM) to pick apart very similar vectors, you’ll want to use it with the winner-take-all mechanism, described in this example.
Another thing you’ll probably want to do is to use it as a heteroassociative memory in order to map the EMG data onto “proper” semantic pointers. The WTA mechanism and heteroassociative configuration can be combined, as illustrated in this example. To demonstrate what I mean, here’s some pseudo code on how you would generate the vocabulary, and use the heteroassociative memory to do the mapping:
network_vocab = spa.Vocabulary(dimensions=SPA_DIMENSIONS, max_similarity=0.1)
# This is your EMG data (remember to normalize first!)
network_vocab.add("EMGGEST1", gesture1_ref_window)
network_vocab.add("EMGGEST2", gesture2_ref_window)
# These are "proper" semantic pointers for each gesture (note that these are randomly generate defaults by NengoSPA)
network_vocab.populate("GEST1; GEST2")
# This is the mapping for the heteroassociative memory
mapping = {
"EMGGEST1": "GEST1",
"EMGGEST2": "GEST2",
}
# The SPA model:
with spa.Network("Classify") as model:
...
# This is the heteroassociative WTA memory
model.assoc_mem = spa.WTAAssocMem(
threshold=0.3,
input_vocab=network_vocab,
mapping=mapping,
function=lambda x: x > 0.0,
)
...
If you want to perform some decision making based on the input EMG data, with the heteroassociative memory, you can then perform this using the NengoSPA-generated semantic pointers instead of the EMG data:
with model:
# Specify the action mapping
with spa.ActionSelection() as action_sel:
spa.ifmax(
"Gesture 1 Selection",
spa.dot(model.assoc_mem, network_vocab["GEST1"]),
spa.sym.GEST1 >> cortex,
)
spa.ifmax(
"Gesture 2 Selection",
spa.dot(model.assoc_mem, network_vocab["GEST2"]),
spa.sym.GEST2 >> cortex,
)
Hi @xchoo, thank you for your reply! It was really helpful and informative and it has helped me better understand the SPA architecture. Your code examples were really helpful as well and helped clear up some confusions I had.
Can I ask some follow up questions on some of the points you mentioned?
Inputs
In your reply you mentioned about the use of the spa.Transcode module being able to use a python function to output the data to drive the model and you provided some code showing how to implement this functionality where a certain piece of data would be outputted within the first 0.5 seconds and then a different piece of data would be outputted after 0.5 seconds. If I wanted to dynamically pass data to my model would you recommend using the data argument provided by nengo_dl (done in this example) or would you recommend using the above approach where you would create a function which returns the data to be fed into the model at each timestep?
Alternative methods
You had mentioned the approach used in Spaun where a classifier was used to classify the visual inputs (would this be both the MNIST images and the task character cues (A0, A1, etc.)?) which are then mapped onto semantic pointers and how for my project I could use a DL or ML network to map the EMG signals onto semantic pointers. Would I be right in saying that for this approach I would be creating a DL network which generates the semantic pointer vectors based on the EMG input? So the neural network is in a way encoding the EMG data into a semantic pointer of predetermined dimensions.
Is this how Spaun achieved it by using this encoding approach? I had read the Spaun 2.0 thesis paper where it talks about Spauns vision module making use of a visual semantic pointer classifier to achieve its tasks, does this semantic pointer classifier implement the same logic where it uses a DL network to encode the image data into a semantic pointer vector?
Also thank you for suggesting the use of a heteroassociative memory network for my classification task. I’m going to look into implementing it as well to see how it performs with my data.
Thank you for your help and suggestions so far its greatly appreciated!
I’d have to double check, but I think the data argument in NengoDL only applies to the sim.fit / sim.train (i.e., the TensorFlow wrapper functions). Since you’ll probably be simulating the network with the .run function, you’ll need to use a node with a (custom) function to feed in your data. I posted some pseudo-code demonstrating how to do this with a Python class in this forum post.
That is correct! The same classifier network was trained on the MNIST images and used with the character cues (A, X, ?, >, <, etc.) as well. Interestingly (and I’ll go into more detail on this later), no additional training was needed for the network to classify the character cues (it was only trained on the MNIST images).
In essence, yes! There are multiple ways of doing this though. One easy approach is to train a DL / ML network to classify your EMG data into a set of output classes. Then you can apply a one-hot encoding schema to those classes to easily turn them into “semantic pointers”. You can then feed these one-hot encoded semantic pointers into a hetero-associative memory to map them into a semantic pointer space that is used by the rest of your model.
In Spaun, a slightly different approach (but essentially the same technique) from the one-hot method was used. Since the MNIST classifier was only trained on the MNIST digits (i.e., the output classes only go from 0 to 9), the one-hot encoding schema couldn’t be used. Fortunately, it turned out that the activity of the second-to-last layer was sufficient to use as the “intermediate” semantic pointer (I referred to this as the “visual semantic pointer” in the Spaun 2.0 thesis). As with the one-hot approach, this “intermediate” semantic pointer was used with a hetero-associative memory to map it on to the Spaun-wide semantic pointer space. I should note that there had to be some scaling applied to the activities of the second-to-last layer to get it into the right magnitudes (see the previous discussion about vector magnitudes) so that the hetero-associative memory could use them properly.
Thank you for your reply, this has been really helpful in better understanding how to use the SPA for my project and the examples you provided and insight offered is greatly appreciated and helpful.