That is correct. The nengo.dists.Choice distribution randomly uniformly chooses values from the given list. Since the given list has only 1 item (100), all of the neurons in the network are initialized to have a “maximum” firing rate of 100Hz. Note that this “maximum” is when the neuron is being presented with an input value of 1, and not the true maximum firing rate (which is 1/tau_{ref}).
This is also correct. And in the code, since the intercepts are initialized to 0, neurons will only start firing when their input values exceeds 0.
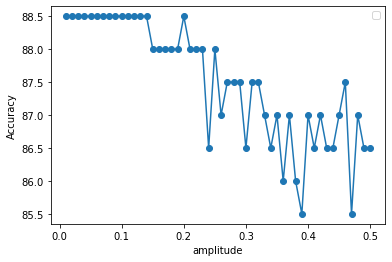
Changing the amplitude of the neuron changes the amplitude of the spikes that are produced by the spiking LIF neuron model. Increasing the spike amplitude has the effect of increasing the amount of information being passed to subsequent neuron layers. Increasing the spike amplitude essentially scales the output of that neuron. I.e., if that neuron was outputting a “1”, doubling the spike amplitude would make it output a “2” (I’ll have to double check if the scaling is linear, but the sake of simplicity, it’s linear in this explanation).
Increasing the spike amplitude itself wouldn’t cause too much of an issue if the network weights are trained to utilize these spike amplitudes. However, if have left do_training = False, then the network has been trained to use the smaller amplitudes, but is then being presented with the bigger spike amplitudes. Logically, this would impact the accuracy of the network, and cause a decrease in the overall accuracy, which is what you see here.
As for the zig-zag nature of the accuracy, this is because you are only looking at the accuracy results of one run of the network. Additionally, the network creation is seeded, so you’re basically running the same network over and over. Because the network is seeded, it could be that for some network amplitudes the network does okay (even if it wasn’t trained for it) just due to spike timings and filtering effects. But, if you increase or decrease the amplitude by a bit, those spike timings could arrive too close or too far apart causing a dip in accuracy.
If you want to get the overall trend of increasing the neuron amplitude, you’ll want to run the network multiple times using different seeds (you’ll need to train up the “base” network with a seed, then increase the amplitude for that seed).