Recently tried to develop RL using Nengo and integrated with open AI gym.
Code is available here
But I have few queries its performance is not so great.
I found DQN using torch and Tensorflow performs really awesome.
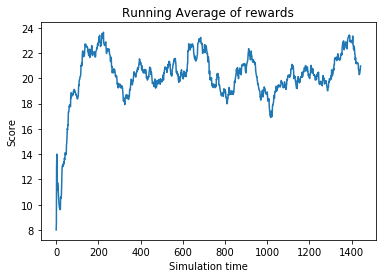
As you can see running average of rewards basically shows Nengo RL agent can balance pole for just 20 to 25 steps.
Nengo is very good cognitive modelling platform.But expecting Nengo to perform as good as like any other neural networks library like Torch or TF is valid(might be valid for NengoDL)?
Hi @ganesh! Right now it looks like your network is using PES to do the learning online. This is quite a different approach from the offline training procedures used in DQN. Both have pros and cons, but in general, an online learning algorithm like PES can be pretty sensitive to the learnin grate, so you could try lowering it to see if you can get out of the plateau you seem to be in.
More structurally, however, the big difference with PES is that it can only be applied to the weights on one connection in the network at a time, whereas DQN and other learning mechanisms can optimize all of the variables in the simulation across many layers in order to improve performance. This allow an algorithm like DQN to build up a big library of experiences over time, while PES could be rather short-sighted and sensitive to recent history.
Nengo can certainly perform as well as other neural networks libraries. The comparison is more clear when you use NengoDL. You could, for example, implement DQN in NengoDL without too much trouble.
Hi Trevor
I tried playing with Learning rate and found slight improvements but not very significant.
But I have one question
So Could we stop online(PES) learning conditionally? like if consistently reward is above certain cut-off then just we could say just stop learning.
You could always route the error signal through a custom nengo.Node(...) that contains whatever logic you would like to gate the error. If the output of the node is zero then no learning will happen (because there is no error), and you can use plain Python code to control the conditions under which this occurs.
Another thing you can try is to replace nengo.PES(...) with nengolib.RLS(...) after doing a pip install nengolib. The RLS learning rule is essentially the same as PES, but is not greedy. It provides the optimal least-squares solution at each time-step by maintaining the full correlation matrix. This is computationally more expensive, but provides better guarantees. However, as @tbekolay mentioned, neither will backpropagate the error through your network – both rules are applied locally to the weights at the given layer, which puts this kind of online learning at a fundamental disadvantage compared to methods that can simultaneously optimize across multiple layers.
If you are interested in a comparison of online RL algorithms then you might want to dig into the details of those other algorithms and see if there’s a way to express them within a Nengo network (e.g., as custom learning rules). If you are purely interested in maximizing performance you might want to switch to nengo_dl and set things up to be analogous to the best model and training setup that you can find.
RLS learning sounds interesting idea I will definitely try.
So I am trying to replicate @tcstewar’s this work with nengo.
this paper presents two models
External Model which learns to use external symbol systematically to optimise cognitive(Foraging) task.
Internal Model which learns to use internal representation(internal symbol like analogies) systematically to optimise cognitive (Foraging) task.
To test Nengo RL I am thinking GYM could be easy to go platform and if it performs optimally with GYM then it might perform with Foraging task which is presented in this paper.
Motivation to use Nengo is because of its claim about biologically plausibility and also it has interesting features like Semantic pointers which I think it could be useful as a internal representation.
So I have nengo implementation of terry’s idea but currently in terms of performance it is not working well.
I have also DQN with pyTorch implementation it is giving some interesting results but then nengo_dl also could give similar results but then it will be just some different implementation of DQN.
So my bigger question with nengo is how biological neuronal system uses internal and external representations to optimise task?
I am also interested in spacial cognition how grid cell place cell kind of structure could be represented using neurons(Internal representation of world). Is there any paper on it?
I hope it’s okay for me to cross-post this from my original post on the RL discussion thread, because that thread seems to been dormant. Having just noticed the activity on this new thread, I figured it might make more sense to post here.
So: I’d like to use RL in Nengo to continue the project I started at last summer’s Brain Camp, where Terry helped me use Nengo to build a simple PID-controller plugin for a quadcopter flight simulator in UnrealEngine4. Since then I’ve replaced the built-in UE4 physics with a dynamics model taken from the literature, which I’ve also translated to Python to enable me to work directly with Nengo. The dynamics model is very simple: you input the four (or six or however many) motor values, and you get back the vehicle state in a form similar to what you’d get from sensors (IMU, altimeter, etc.). The idea would be to train up a Nengo-based RL network using this dynamic model and a simple reward metric (perhaps distance covered within some altitude band, to avoid ballistic maneuvers). Then the Nengo controller would be run directly in the actual simulator, using a general Python plugin I’m working on, for a live demo of Nengo flying the quadcopter. The ultimate goal would of course be using Nengo (running on an ODROID, Jetson, or whatever) to fly a real 'copter.
I’ve been reading through Daniel’s papers to get a general sense of how to approach RL with Nengo, but if someone can point me to one or more concrete examples that I can play with, that’d be a big help.
Hi, sorry for bumping old thread. I was looking for an implementation of DQN with NengoDL. Maybe it is my lack of experience in Nengo, but I found it very difficult to build one.
Is there any example of how to implement DQN with NengoDL?