This resolves my doubt. Thanks! I can see the summed up spikes values (i.e. 2/dt) when x2 = x1 = 0.9. Upon using the array slicing feature on Nodes, I can see that I can access the spiking activity of both ensembles (1 neuron each). Although, I attempted to calculate the ISI for a single neuron in the mean time and my following code fails with error: UnboundLocalError: local variable 'prev_spk_time' referenced before assignment. Seems like calculating ISI is not straightforward as I anticipated. Code:
I have defined the variable prev_spk_time globally such that it should be accessible to the function _get_isi(). Now, the function _get_isi() is called/executed at every time-step; so any variable defined in its scope will get re-initialized again and again, thus losing any information stored at the previous time-step. Therefore I tried using an external variable prev_spk_time to store the integral time-step of the previous spiking activity (relative to the current activity), but the compilation complains with the above-mentioned error. Is it possible to compute ISI within a Node?
With respect to Nengo-DL representation of values, I was actually having such premonition of highly tuned neurons,
and the above gives me more info; although I do not know the exact maths behind it, i.e. the mathematical steps on how does the TF trained weights results in highly tuned values of gains and biases. I do see here and here that one can calculate the max_rates and intercept from gain and bias and vice versa of course. Can you please point me to the code which has the mathematics of tuning these parameters from the TF learned weights? A short example/explanation would also be very helpful.
Next thing which was on my mind is… if the neurons (be it SpikingReLU or LIF in Nengo-DL domain) are highly tuned to represent a value, do they spike every time-step to approximate the value? Or is there some gap (ISI) in their spiking activity e.g. a neuron (with radius -1 to 1) representing 0.9 would spike more often than a neuron representing the value 0.5? I mean… if the neuron spikes every time-step (for SpikingReLU of course) or every other possible time-step (once the refractory period is over for LIF neurons) then the Loihi Board will be active all the time, thus no sparsity and little/no power savings? I did check the spiking activity of few randomly selected SpikingReLU neurons (after the TF trained network was converted) and I did see some gap between spiking in those random neurons, and I wanted to confirm this behaviour theoretically with you. Please let me know accordingly.
For normal Nengo ensembles (with NEF computation), I do see gaps between the spiking activity of each neuron when representing values of varied magnitude, although the approximation of the “smaller magnitude” values with just one neuron is not very accurate, which I guess… this problem shouldn’t exist in Nengo-DL due to highly tuned neurons as you explained.
This behaviour is consistent with Python’s handling of scopes for variables. If you want to use a global variable to store an external value, you’ll need to define the variable as global:
def my_func(t, x):
global prev_spk_time
... # rest of code
You can also do things like use a function parameter that’s a list:
def my_func(t, x, prev_spk_time=[0]):
if prev_spk_time[0] == None ... # example use
... # rest of code
When TF trains weights, it modifies connection weights between individual layers and between a bias layer and an activation layer. Since the operations are linear, modifying the connection weights between layers adds a multiplicative scaling term to a neuron’s gain. Likewise, modifying the connection weights between a bias layer and the neuron adds an additive scaling term to the neuron’s bias. Changing the gain and bias of a neuron has the effect of modifying the neuron’s response curve. You can also look at how the currents are calculated for neurons, you’ll see how this overall affects the currents being computed for the neuron.
No. The neuron’s will still spike at whatever firing rate is representative of the value it is representing. Remember that the concept here is that a specific firing rate of a neuron maps on to a specific output value for that neuron. And the mapping is determined by the neuron’s activation function.
Hello @xchoo, thank you for pointing out the global declaration, silly me that I had completely forgotten about it.
About the following,
this makes things a little clearer to me. Taking an example of a simple model with InputLayer, followed by a Dense layer and then an Output layer; one spiking neuron in the Dense layer has weighted inputs from all the inputs in the InputLayer (i.e. many to one connection for a single neuron in Dense layer). Now, let’s talk about just that one particular spiking neuron. As per the architecture it can receive a range of inputs from the InputLayer and will represent the weighted sum of those inputs, thus representing a range of weighted sums. According to you, the connection weights (between layers and between bias layer and activation layer) influence that single neuron’s gain and bias by multiplication of a scaling term (say term1 x gain) and addition of a scaling term (say term2 + bias) respectively. My question is, are these two terms term1 and term2 representative of all the individual connection weights from InputLayer to that single spiking neuron in Dense layer? If yes, how are these scaling terms term1 and term2 computed? If it involves a lot of details, please don’t bother mentioning all of them, just a confirmation of my first question will do for now.
Next, after the desired computation of a spiking neuron’s gain and bias, as you said, it will influence its response curves; so I guess… that particular spiking neuron is tuned to represent a range of weighted sums (thus indirectly representing the range of raw inputs from InputLayer). Therefore, at extremes, a particular weighted sum will result in maximal spiking of the neuron (say 200Hz) and say… another weighted sum will result in zero spiking of neuron (or just above zero which represents minimal spiking). Thus the spiking neuron is now tuned such that it can accurately represent any value in the weighted sums range over a sufficiently long period of network simulation. Or in other words… in light of the following:
the filtered spike signal saturates to the expected representative value. Right?
Yes and no. Conceptually, yes, term1 and term2 would be representative of all of the individual connection weights. But in practice, the computation is done using a matrix multiplication, so these weights are separate (i.e., individual elements in the connection weight matrix), and the matrix multiplication operation puts them together, and there is no term1 or term2 value that is calculated specifically.
Thanks @xchoo for the insights. I understand there’s more to the actual calculation to tune the spiking neurons in Nengo-DL, but I will rest my case here for the time being with an abstract understanding obtained so far. Thank you very much for this informative discussion!
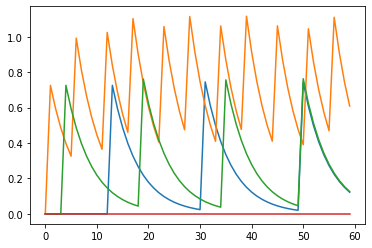
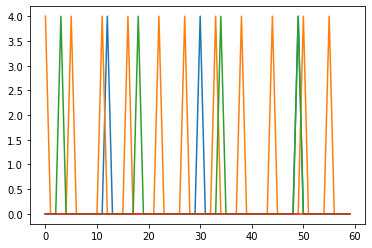
Hello @xchoo, just trying to confirm my interpretations with you on the following plots. These are obtained from a trained and converted Nengo-DL network and are the outputs of the first Conv layer. The converted network has a scale_firing_rates value of 250. Below is the code I used to collect spikes and corresponding smoothed values from the neurons in the Ensemble corresponding to the first Conv layer. As discussed above, the spiking neurons are supposed to be highly tuned to represent the scalar values.
First plot corresponds to the smoothed values from the spikes of 4 neurons.
plt.plot(sim_data[conv0_values][0][:,0:4])
and this second plot corresponds to the spikes of those same 4 neurons.
plt.plot(sim_data[conv0_spikes][0][:,0:4])
The spikes have amplitudes 4 as they were scaled else I believe, they should be of amplitude 1.
From the first plot, it seems that even if the neurons are trying to best represent the scalar value, they are actually fluctuating a lot around their to be represented value. However, the range of fluctuations vary, i.e. the orange neuron is trying to represent a higher value and as can be seen in the second plot, the orange neuron is spiking faster than others.
Overall, what I draw from both plots is that neurons which have to represent a higher value, they have to spike comparatively faster than the others. This same story should hold with neurons in later/deeper Ensembles… right? Please let me know your thoughts as well.
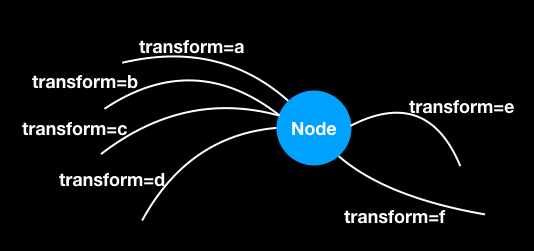
Just needed a quick confirmation with respect to the following picture:
The above Node receives four inputs as shown, with inputs related to transform=a and transform=d directly from another Nodes (which again just receives input from neurons and outputs the same input to two objects - one being this Node in the question and other being an Ensemble). Inputs related to transform=b and transform=c are from an Ensemble and the outputs related to transform=e and transform=f are to a Node (which is exactly a same instance as this) and an Ensemble.
Functionality wise, the above Node simply sums the 4 inputs and outputs two transformed copies of the summed input. Is this a Passthrough Node? From this source, it appears to be a pass-through node, therefore just confirming?
Another question, I know it might be bit elusive to answer, but will a network composed of such Nodes (assuming it’s a pass-through) and Ensembles be all capable of running on Loihi (where the input to the network is simply from Nodes which output exact copies of the input (i.e. no function computation) from previous Ensembles’ neurons?
Yes. The node configuration you have in your picture would be considered a passthrough node.
In theory, if your network only contains ensembles and passthrough nodes, then the entire thing will run on Loihi with only the network inputs and network probes as I/O to and from the Loihi board / chips. In practice however, my previous statement assumes that the number of neurons, and the dimensionality of the connection weight matrices are within the limits of the Loihi system. Although, if they do exceed the Loihi limits, I think NengoLoihi will warn you of this when you build the simulator object.
Thanks for confirming @xchoo, and yes, the number of neurons in such a Net is well below the limits of Loihi, and the transforms are simply scalars, so I should be good here too.