I would like to play with different neuron types that are available in nengo_extras. However, I would like to use it in nengoDL for example in the MNIST example. Is it possible to use nengo_extras neurons in nengoDL? If no? are there any different neuron types available in nengoDL? I could not find it in the documentation.
In theory, it is possible to use the neurons from NengoExtras in a NengoDL simulation, but it would require some work to do so. You would need to re-write the neuron dynamics in TensorFlow code since NengoDL uses TensorFlow to simulate the neuron models.
Here are some forum threads that may be helpful to you if you wish to pursue this approach:
Yes! NengoDL does support multiple neuron types. You can find documentation on the (default) supported neuron types here! NengoDL also supports all of the neurons that are available natively in Nengo (documentation here).
Thank you for sharing the useful links.
This leads me to another question. If I am changing the neuron type it only changes the neuron type in the testing phase, right? In the training phase, SoftLIF is used by default? am I right?
It depends on how you are defining your model. NengoDL follows the TF implementation where you can specify the activation type for your layers within the model itself. If you create a model with something like this:
x = tf.keras.layers.Dense(1, activation=tf.nn.tanh)(...)
your model will be trained using the tanh neuron model. The one major difference between the training and testing phases (for NengoDL) is that spiking neuron types can only be use in the testing / running phase. In the training phase the rate-approximations of the spiking neurons are used.
@xchoo in the list of NengoDL neuron types we have softLIFRate and LeakyRelu. But reading their description they don’t seem to be spiking neurons. In the spiking version, we have only LIF and SpikingLeakyRelu for nengoDL? What about the neuron types that are available for nengo core here ? can we use them in nengoDL?
NengoDL has support for the RegularSpiking, StochasticSpiking, and PoissonSpiking wrappers in Nengo. These wrappers provide three different ways of turning any rate neuron into a spiking neuron. NengoDL currently supports the LIFRate, RectifiedLinear, Sigmoid, and Tanh rate neurons included in Nengo. This means you can do something like nengo.RegularSpiking(nengo.Tanh()) to create a spiking Tanh neuron and use that in NengoDL. (Note that it’s probably better to use nengo.LIF() rather than nengo.RegularSpiking(nengo.LIFRate()) in NengoDL, since the former will use the SoftLIF gradient whereas the latter will not; see this issue.)
Unfortunately, NengoDL does not have native TensorFlow support for AdaptiveLIF, AdaptiveLIFRate, and Izhikevich neurons. For these neurons, NengoDL runs them in Numpy, which works fine for the forward pass (though it is slower), but does not support differentiation (backwards pass). So if you want to use any of these in your MNIST network, you’ll need to write a custom NengoDL builder that does the computation in TensorFlow (see here for the NengoDL implementations for the supported types, plus the links that @xchoo pointed to above).
@Eric I have been playing with these neuron types for quite a few days. I would like to study more about these wrappers’ regular, stochastic and Poisson spiking.
How they convert the non-spiking neuron to a spiking one. Do we have any paper references for them?
After training the network with the Poisson spiking wrapper, I am getting different accuracy results Evaluating the same trained network multiple times. Why is it so?
One place to start for reading is A Spike in Performance. It describes what goes on for RegularSpiking.
All three wrappers work by starting with some function/system that outputs an instantaneous firing rate at each point in time. This can be a function (e.g. ReLU, f(x) = max(x, 0)) where the output only depends on the input at the current point in time, or a dynamical system (e.g. AdaptiveLIFRate in Nengo) where the output firing rate depends on the history of inputs. That’s what the “wrapped” neuron class does: it provides this instantaneous firing rate.
Given that instantaneous rate, the PoissonSpiking wrapper is perhaps the easiest to understand: it just uses it to sample from a [Poisson distribution], where the lambda value of the distribution is this instantaneous firing rate.
RegularSpiking takes the instantaneous firing rate and integrates it multiplied by a timestep dt. For example, if our firing rate is 5 Hz, that corresponds to one spike every 200 ms. With a timestep of 1 ms, that’s one spike every 200 timesteps. RegularSpiking will integrate this so that one spike happens exactly every 200 timesteps given a constant instantaneous firing rate of 5 Hz.
StochasticSpiking is kind of a mix between the two, and the difference mostly shows up when neurons can spike more than once per timestep. Essentially, if the instantaneous firing rate says we should have e.g. 2.4 spikes per timestep, than on a given timestep we’d always have at least 2 spikes, and a 0.4 probability (40% chance) of a third spike.
The reason you get different results with PoissonSpiking is because it’s stochastic, so it will output different spike trains each time. You can set the seed on the nengo.Simulator to seed this randomness so it’s the same each time.
I have found one conversion example explained in here. However, what is this gain parameter? (you set it to 3 for Tanh in the example).
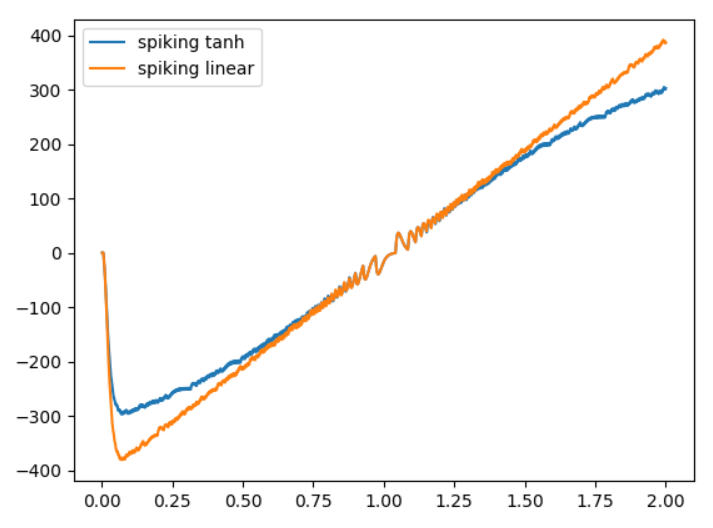
Normally the conventional Tanh starts from -1 to 1. The spiking one starts from 0 and then for few time steps it is 0 and then it starts going down towards -400 and starts behaving like Tanh in a spiking way. I this because it starts accumulating current in the start?
Now how would an input value be mapped? How would this mapping work? For instance, I have an input value of 1 it would be mapped to approx. to 0.77 in conventional Tanh. What about in spiking version? How would this mapping look like?
I am sorry if this question has been already answered on the forum.
If you plot the tanh function, you’ll notice that the slope of the curve at the midpoint is roughly 45 degrees. The gain parameter here changes this slope, and having a bigger gain value increases the “steepness” of this slope. You can experiment with it yourself by changing the gain in the code to see what effect it has.
That is essentially correct. In Nengo, if you do not specify any defaults, the neurons will start with a blank state (i.e., 0 input current, 0 membrane current, etc.). This means that when the simulation starts, the neurons aren’t doing anything (and outputs no spikes), and it takes a few timesteps for the neuron to get going. We refer to these as “startup transients”.
The mapping would be similar in the spiking version, with the addition that the “output value” is scaled by the firing rate. As an example, if you had a “conventional” tanh function (i.e., the gain=1), an input value of 1 would have an output value of 0.77. In the spiking version, the output would be this value multiplied by the maximum firing rate. In @Eric’s example code, the maximum firing rate of the tanh neuron is 400Hz, so the output of such a neuron with an input of 1, would be 400 \times 0.77 \approx 308.
If you change the gain in the code to 1, and run Eric’s code, you will see a graph like this:
The gain parameter here changes this slope, and having a bigger gain value increases the “steepness” of this slope. You can experiment with it yourself by changing the gain in the code to see what effect it has.
Does this mean that we can somehow control the response of the neuron by adjusting this gain parameter?
My question is then when I am using tanh in nengoDL then this gain parameter is learned by the network during training?
Thank for the rest of the explanations.
But I may sound stupid, but just want to clarify this tanh and others non-spiking neurons are simulated one or built with some mathematical formulations?
In some respects yes. You can definitely change the behaviour of the neuron by changing the gain value, that’s why it is made available to you in the API.
NengoDL doesn’t allow you to train the gains directly. The gain of the neuron is contained within the connection weights between the layers and by training those weights, you indirectly train the gains.
I’m not exactly sure what you are asking here? What do you mean by “simulated” as opposed to “built with a mathematical formulation”? All of the neurons in Nengo are simulated, which is to say that their behaviour is the result of evaluating a mathematical formula (that describes the neuron) over a period of time.

 This is what I wanted to know
This is what I wanted to know