Q2. In a (TF trained and converted) Nengo-DL model (with all Nengo objects and no TensorNodes), what are the recommended values of scale_firing_rates? I read about quantization errors (I don’t remember the source) which perhaps should be accounted for while scaling the firing rates. So what is this quantization error? is it that a neuron should ideally fire spikes at some designated frequencies, e.g. 100Hz, 200Hz, 250Hz, 500Hz to lower down the quantization error? Also, what is it’s relation with the scale_firing_rates parameter and others (if at all there’s one)?
I do understand that when we set dt=0.001, then the max firing rate at which a neuron can spike is 1000Hz (i.e. one spike every tilmestep). So I don’t think there’s any point in scaling the firing rates infinitely, because at a certain value of scale_firing_rates all the neurons in a model will saturate. Please let me know.
There is no “ideal” spiking firing rate that will apply to all NengoDL models, and finding the scale_firing_rate value that works for your model involves a lot of trial and error.
You will find that, generally, as you increase the value of scale_firing_rates, the performance of the network will increases. However, you will observe a point where there is minimal increase in model accuracy even with an increase in the scale_firing_rates value. At this point, you may consider the scale_firing_rates value to be “good enough”, but it’s really up to the designer of the model to decide what point this should be. Particularly, if you are implementing the model on actual spiking hardware, you’ll want to consider if the increase in performance is worth the increase in power draw due to the extra spiking happening in the network.
The scale_firing_rates value also depend on the specifics of the task that the model is being employed to solve. For some tasks, you can get good accuracy with lower firing rates. For others (particularly ones that present inputs over longer periods) you might find that a larger scale_firing_rates value (along with synaptic filtering) is needed to retain and propagate the correct information through the network to get desirable results. Once again, it’s one of those instances where you’ll need to experiment with your network and with the scale_firing_rates parameter to figure out what is “optimal” for your network and task.
This is only true for some neuron types (like the LIF neuron), where the maximum number of times that it can spike is once per timestep. However, neurons like the SpikingRectifiedLinear neuron (see your previous question about NengoDL) are able to spike multiple times per timestep, which means that the scale_firing_rates values for such neurons have no upper bound, since increasing the scale_firing_rates parameter just makes it spike more times per timestep.
Thank you @xchoo for you explanation on recommended values of scale_firing_rates. I get it now, especially the part with LIF neurons (and alike) where they spike only once in a time-step. And apologies for missing the point of SpikingRectifiedLinear neurons spiking more than once per time-step. In fact, one can understand this intuitively too, i.e. given that SpikingRectifiedLinear neurons are spiking counterparts of rate based ReLU neurons, and since ReLU neurons don’t have an upper bound on its values, SpikingRectifiedLinear shouldn’t have one too (in terms of spikes per time-step).
Although, I couldn’t get the reference of quantization errors. What are these with respect to Nengo-DL architecture? I am probably being vague (or even wrong) here as I don’t have sufficient information on it.
The term “quantization” can mean several things, so I’m not entirely sure what you are referring to here. Quantization could mean the process of converting floating point representations (e.g., for the weights) to fixed point or integer representations. If this is what you mean, then NengoDL doesn’t yet support this functionality. You’ll need to use another tool, like TFLite to train a model with quantized weights.
Alternatively, quantization could be used to describe the process of spiking, where you can consider a train of spikes to be a quantized (1-bit) version of a continuous signal. As for this interpretation, @drasmuss (our lead NengoDL dev) can correct me if I am wrong, but currently, NengoDL trains all models (even spiking ones) using rate neurons, and only the evaluation of the models are done with the spikes. This being the case, the “quantization error” would only appear in the evaluated model, and not as part of the training process.
Another dev (@Eric) suggests that you ran across the term in this paper?
Hello @xchoo, I was able to get more context about quantization errors. The paper you cited is not the one (it’s relatively new and looks an interesting read), but here’s the source. It’s written that We pick 150 because above 150 Hz, the quantization error in Loihi neurons becomes significant.. I wanted to understand what this sentence is trying to convey.
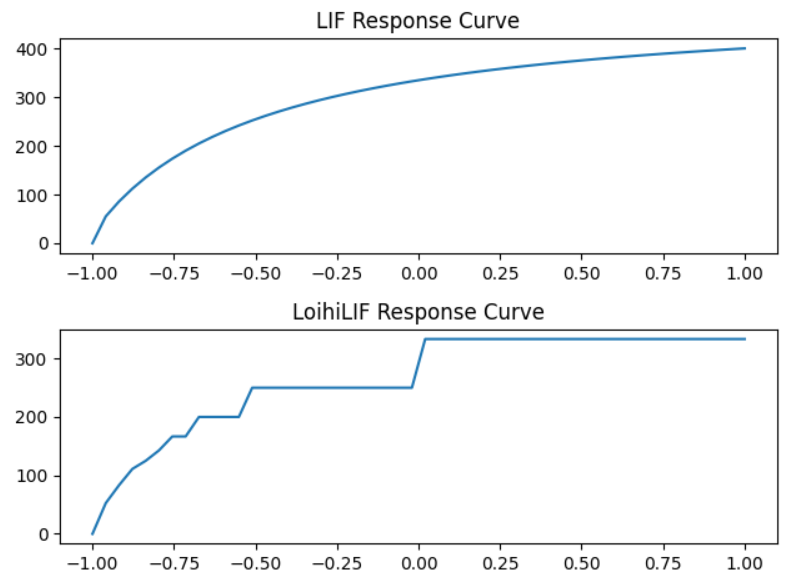
We have already established that Loihi neurons fire only once per time-step. Thus, in case of LoihiSpikingRectifiedLinear() it can fire max at 1000Hz (dt=1ms), and in case of LoihiLIF, depending on its refractory period as well as gain etc. it may fire at 250Hz max (or any such number, but certainly less than 1000Hz). Now, one can assume that any firing rate between 1Hz to 1000Hz or 1Hz to 250Hz is feasible in nengo Loihi for a variety of inputs. But it seems no, this is not the case. Upon further read, here I found a beautiful illustration of quantization/discretization of firing rates in Loihi for both the types of aforementioned neurons. What property of Loihi board/neurons results in quantization of its firing rates?
And, let’s say that a SpikingRectifiedLinear() neuron fires at 700Hz (due to its no refractory period property and multiple spikes per time-step, it can assume any discrete firing rate), then from the pictorial illustration referred earlier, it seems that LoihiSpikingRectifiedLinear() will spike at 400Hz or 450Hz for the same input. So is there any provision made for LoihiSpikingRectifiedLinear() neurons to compensate for this firing rate quantization error (i.e. 700Hz - 450Hz) or is there all what’s mentioned in the corresponding article to minimize the quantization error? Please let me know.
I think I have got this one. A Loihi neuron can fire a spike once every time-step. Now the interval between consecutive firing is always going to be an integer. E.g. suppose a Loihi neuron takes x=3 time-steps to reach threshold (thus fire a spike) and next y=2 time-steps as refractory period, then it can be considered that it fires every 5 time-steps, thus it will fire at 200Hz (in a duration of 1000 ms/time-steps of course). Thus, the sum of x+y is always an integer and we get certain quantized firing rates for every possible value of x+y. E.g. 250Hz for x+y = 4, 200Hz for x+y = 5, 166Hz for x+y = 6 and so on. We cannot expect to have every possible firing rate (i.e. 249Hz, 248Hz, … ). This stands true for any type of Loihi neuron. Silly me!
About the next question on accounting for quantization errors, I think it’s an active research topic for now. The paper mentioned earlier does talk about the errors due to quantizing neuron activity. This seems related to my query. But anyways… will be happy to hear more about other existing approaches to minimize the quantization errors if any in the light of the following question.
Yeah, you’ve got it. Loihi neurons have to have integer firing periods because of the hard voltage reset (the voltage is set to zero after a spike). “Quantization error” is definitely not the best term, but that’s what it’s referring to. If the firing threshold was subtracted from the voltage when a neuron spikes, then this problem would not occur.
The approach that we normally take to account for this is a) don’t let firing rates get to high, to avoid the worst effects, and b) account for the specific tuning curve of the Loihi neurons when solving for network weights (whether that’s decoders, DNN weights, whatever).
One other approach that we don’t typically use, but is an option, is adding noise to the voltages. This will allow a neuron given a constant input to have different numbers of timesteps between spikes, with the idea that over time, things will average out to a better answer. However, too much noise will interfere significantly with your signal, so there’s a tradeoff.
Thank you @Eric for looking into it. Can you please elaborate on the following?
Does it mean that you deliberately choose tuning curves of some selective neurons in an ensemble whose firing rate (at x = -radius or x = radius) are somewhat closer to the desired firing rate (which are continuous in integers, e.g. 247Hz, 248Hz), thus lowering down the quantization errors which would have been otherwise resulted inadvertently due to random choice?
This following
sounds an excellent idea to have irregular periods of spiking, but one has to be careful with it. I agree.
I believe what @Eric is referring to is to use the LoihiLIF neuron response curves when you are doing the process involved in solving or training the network connection weights. Here’s some code test_loihi_tuning_curves.py (918 Bytes), and graphs illustrating the differences between the response curves for the Loihi / “standard” Nengo LIF neurons:
For NEF networks, we typically use the nengo.LIF response curves when solving for the ensemble decoders and then when we go to simulate the neurons on the Loihi chip, they are substituted with the LoihiLIF neurons on chip. However, because of this, the solved decoders aren’t optimized for the LoihiLIF neuron activations (especially for high firing rates), and this is where the “quantization errors” appear.
For NengoDL trained networks, a similar process leads to the same errors. It is common practice to use the nengo.RectifiedLinear or tf.ReLU activation functions during the training phase of the network. This is then converted to the LoihiSpikingRectifiedLinear neurons before it is simulated on the Loihi chip. Once again, because the response curves of the neurons used during the training process don’t 100% replicate the “quantization” behaviour of the Loihi neurons, “quantization errors” occur during the simulation.
What Eric is suggesting is to directly use the Loihi specific neurons when the network weights are solved for / trained for – as opposed to the common practice of using a “standard” neuron proxy and then only swapping in the Loihi specific neurons when it comes time to simulate it on the Loihi chip.