Hi, I an new to Nengo. I was wondering whether it’s it possible to create a spiking neural network for a CSV dataset in Nengo for purposes of classification. Currently, I see only examples for images, in particular the MNIST dataset. Is there any examples you can provide or a method to convert a keras model for a CSV dataset into a spiking neural network model instead of images. Thanks.
Hello @CodeHelp1, why not! You can absolutely use the concepts from the MNIST example to work on your CSV data. By the following,
I guess… you mean Nengo-DL (for deep learning) and not Nengo per se. If yes, you can find the TF-Keras supported layers which are convertible in Nengo-DL here. As can be seen, Nengo-DL supports conversion for tf.keras.layers.Dense layers and tf.keras.layers.ReLU layers as well. So in case your network has to be built of Dense layers on your CSV data, you can definitely do that, train it in TF-Keras and then convert it to spiking one by Nengo-DL Converter (as you see in MNIST examples).
I’ve got a model here, but I’m really not sure how to convert it using the documentation.
import zipfile
with zipfile.ZipFile("/content/drive/MyDrive/grasp-and-lift-eeg-detection2/test.zip","r") as z:
z.extractall(".")
with zipfile.ZipFile("/content/drive/MyDrive/grasp-and-lift-eeg-detection2/train.zip","r") as z:
z.extractall(".")
from sklearn.model_selection import train_test_split
import numpy as np
import pywt
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.linear_model import LogisticRegression
from glob import glob
import scipy
from scipy.signal import butter, lfilter, convolve, boxcar
from scipy.signal import freqz
from scipy.fftpack import fft, ifft
import os
from sklearn.preprocessing import StandardScaler
def wavelet_denoising(x, wavelet='db2', level=3):
coeff = pywt.wavedec(x, wavelet, mode="per")
sigma = (1/0.6745) * madev(coeff[-level])
uthresh = sigma * np.sqrt(2 * np.log(len(x)))
coeff[1:] = (pywt.threshold(i, value=uthresh, mode='hard') for i in coeff[1:])
return pywt.waverec(coeff, wavelet, mode='per')
def madev(d, axis=None):
""" Mean absolute deviation of a signal """
return np.mean(np.absolute(d - np.mean(d, axis)), axis)
#############function to read data###########
def prepare_data_train(fname):
""" read and prepare training data """
# Read data
data = pd.read_csv(fname)
# events file
events_fname = fname.replace('_data','_events')
# read event file
labels= pd.read_csv(events_fname)
clean=data.drop(['id' ], axis=1)#remove id
labels=labels.drop(['id' ], axis=1)#remove id
return clean,labels
def prepare_data_test(fname):
""" read and prepare test data """
# Read data
data = pd.read_csv(fname)
return data
from sklearn.preprocessing import StandardScaler,MinMaxScaler
scaler= StandardScaler()
def data_preprocess_train(X):
X_prep=scaler.fit_transform(X)
#do here your preprocessing
return X_prep
def data_preprocess_test(X):
X_prep=scaler.transform(X)
#do here your preprocessing
return X_prep
subjects = range(1,6)
from glob import glob
import pandas as pd
ids_tot = []
pred_tot = []
X_train_butter = []
from sklearn.model_selection import train_test_split
import numpy as np
###loop on subjects and 8 series for train data + 2 series for test data
y_raw= []
raw = []
y_rawt= []
rawt = []
for subject in subjects:
################ READ DATA ################################################
fnames = sorted(glob('train/subj%d_series*_data.csv' % (subject)))
# fnames = glob('../input/train/subj1_series1_events.csv')
# fnames = glob('../input/train/subj1_series1_data.csv')
for fname in fnames:
data,labels=prepare_data_train(fname)
raw.append(data)
y_raw.append(labels)
for fname in fnames:
with open(fname) as myfile:
head = [next(myfile) for x in range(10)]
X = pd.concat(raw)
y = pd.concat(y_raw)
#transform in numpy array
#transform train data in numpy array
X_train =np.asarray(X.astype(float))
y_train = np.asarray(y.astype(float))
from sklearn.preprocessing import StandardScaler,Normalizer,MinMaxScaler
scaler= StandardScaler()
def data_preprocess_train(X):
X_prep=scaler.fit_transform(X)
#do here your preprocessing
return X_prep
fs = 500.0
lowcut = 7.0
highcut = 30.0
x_train_butter=wavelet_denoising(X_train)
x_train=data_preprocess_train(x_train_butter)
splitrate=-x_train.shape[0]//5*2
xval=x_train[splitrate:splitrate//2]
yval=y_train[splitrate:splitrate//2]
xtest=x_train[splitrate//2:]
ytest=y_train[splitrate//2:]
xtrain=x_train[:splitrate]
ytrain=y_train[:splitrate]
import pywt
import pandas as pd
import numpy as np
def wavelet_denoising(x, wavelet='db2', level=3):
coeff = pywt.wavedec(x, wavelet, mode="per")
sigma = (1/0.6745) * madev(coeff[-level])
uthresh = sigma * np.sqrt(2 * np.log(len(x)))
coeff[1:] = (pywt.threshold(i, value=uthresh, mode='hard') for i in coeff[1:])
return pywt.waverec(coeff, wavelet, mode='per')
def madev(d, axis=None):
""" Mean absolute deviation of a signal """
return np.mean(np.absolute(d - np.mean(d, axis)), axis)
signal=pd.read_csv('train/subj1_series1_data.csv')
signal = signal.drop("id", axis=1)
filtered = wavelet_denoising(signal, wavelet='db2', level=3)
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(8,5))
ax.plot(signal.iloc[:10000,1], label='signal', color="b", alpha=0.5,)
ax.plot(filtered[:10000,1], label='reconstructed signal',color="k")
ax.legend(loc='upper left')
ax.set_title('Denoising with DWT')
plt.show()
import seaborn as sns
ye=pd.DataFrame(y_train)
ye.columns=["Handstart ","Grasping ","Lift ","Hold ","Replace ","Release"]
categories = list(ye.columns.values)
sns.set(font_scale = 1)
plt.figure(figsize=(15,8))
ax= sns.barplot(categories, ye.iloc[:,0:].sum().values)
plt.title("Number of samples labeled as active (1) out of {0} length data".format((ye.shape[0])),fontsize=20)
plt.ylabel('Number of events', fontsize=18)
plt.xlabel('Event Type ', fontsize=12)
#adding the text labels
rects = ax.patches
labels = ye.iloc[:,0:].sum().values
for rect, label in zip(rects, labels):
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2, height + 5, label, ha='center', va='bottom', fontsize=10)
plt.show()
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM, BatchNormalization, Conv2D, Flatten, MaxPooling2D, Dropout
from keras.optimizers import Adam
from sklearn.metrics import roc_curve, auc, roc_auc_score
from sklearn.metrics import classification_report,confusion_matrix,accuracy_score,roc_curve,auc
import tensorflow as tf
import numpy as np
load = 1
time_steps = 1000
subsample = 50
model = Sequential()
model.add(Conv2D(filters = 64, kernel_size = (7,7), padding = "same", activation = "relu", input_shape = (time_steps//subsample, 32, 1)))
model.add(BatchNormalization())
#model.add(MaxPooling2D(pool_size = (3,3)))
model.add(Conv2D(filters = 64, kernel_size = (5,5), padding = "same", activation = "relu", input_shape = (time_steps//subsample, 32, 1)))
model.add(BatchNormalization())
#model.add(MaxPooling2D(pool_size = (3,3)))
model.add(Conv2D(filters = 64, kernel_size = (3,3), padding = "same", activation = "relu", input_shape = (time_steps//subsample, 32, 1)))
model.add(BatchNormalization())
#model.add(MaxPooling2D(pool_size = (3,3)))
model.add(Flatten())
#model.add(Dropout(0.2))
model.add(Dense(32, activation = "relu"))
model.add(BatchNormalization())
# model.add(Dropout(0.2))
model.add(Dense(6, activation = "sigmoid"))
adam = Adam(lr = 0.0001)
model.compile(optimizer = adam, loss = "binary_crossentropy", metrics = ['accuracy','mse'])
model.summary()
import numpy as np
load = 1
time_steps = 1000
subsample = 50
model = Sequential()
model.add(Conv2D(filters = 64, kernel_size = (7,7), padding = "same", activation = "relu", input_shape = (time_steps//subsample, 32, 1)))
model.add(BatchNormalization())
#model.add(MaxPooling2D(pool_size = (3,3)))
model.add(Conv2D(filters = 64, kernel_size = (5,5), padding = "same", activation = "relu", input_shape = (time_steps//subsample, 32, 1)))
model.add(BatchNormalization())
#model.add(MaxPooling2D(pool_size = (3,3)))
model.add(Conv2D(filters = 64, kernel_size = (3,3), padding = "same", activation = "relu", input_shape = (time_steps//subsample, 32, 1)))
model.add(BatchNormalization())
#model.add(MaxPooling2D(pool_size = (3,3)))
model.add(Flatten())
#model.add(Dropout(0.2))
model.add(Dense(32, activation = "relu"))
model.add(BatchNormalization())
# model.add(Dropout(0.2))
model.add(Dense(6, activation = "sigmoid"))
adam = Adam(lr = 0.0001)
model.compile(optimizer = adam, loss = "binary_crossentropy", metrics = ['accuracy','mse'])
model.summary()
def valgenerator():
while 1:
batch_size=32
x_time_data = np.zeros((batch_size, time_steps//subsample, 32))
yy = []
for i in range(batch_size):
random_index = np.random.randint(0, len(xval)-time_steps)
x_time_data[i] = xval[random_index:random_index+time_steps:subsample]
yy.append(yval[random_index + time_steps])
yy = np.asarray(yy)
yield x_time_data.reshape((x_time_data.shape[0],x_time_data.shape[1], x_time_data.shape[2],1)), yy
import time
start=time.time()
def generator(batch_size):
while 1:
x_time_data = np.zeros((batch_size, time_steps//subsample, 32))
yy = []
for i in range(batch_size):
random_index = np.random.randint(0, len(xtrain)-time_steps)
x_time_data[i] = xtrain[random_index:random_index+time_steps:subsample]
yy.append(ytrain[random_index + time_steps])
yy = np.asarray(yy)
yield x_time_data.reshape((x_time_data.shape[0],x_time_data.shape[1], x_time_data.shape[2],1)), yy
history =model.fit_generator(generator(32), steps_per_epoch = 600, epochs = 50,validation_data=valgenerator(),
validation_steps=200)
print('training time taken: ',round(time.time()-start,0),'seconds')
Any help on conversion would be appreciated. Thanks…
Hello @CodeHelp1, you are on the right path. Once you have trained your model i.e. model.fit(...) or model.fit_generator(...), you can simply convert it as follows:
sfr = 20
ndl_model = nengo_dl.Converter(
model,
swap_activations={
tf.keras.activations.relu: nengo.SpikingRectifiedLinear()},
scale_firing_rates=sfr,
synapse=0.005,
inference_only=True)
and then create the test data accordingly i.e. tile each of the test samples for n_steps (the presentation time to the spiking Nengo-DL network). This article might give you more context with your approach.
There’s another approach too where you can… after creating a TF model:
model = tf.keras.Model(inputs=input, outputs=dense1)
simply convert it and train it in Nengo-DL context (instead of TF which is your current approach) as follows:
converter = nengo_dl.Converter(
model,
swap_activations={tf.nn.relu: nengo.RectifiedLinear()},
)
net = converter.net
nengo_input = converter.inputs[input]
nengo_output = converter.outputs[dense1]
# run training
with nengo_dl.Simulator(net, seed=0) as sim:
sim.compile(
optimizer=tf.optimizers.RMSprop(0.001),
loss={nengo_output: tf.losses.SparseCategoricalCrossentropy(from_logits=True)},
)
sim.fit(train_images, {nengo_output: train_labels}, epochs=10)
# save the parameters to file
sim.save_params("mnist_params")
Note that the above training is still done with rate neurons (nengo.RectifiedLinear()) and not the spiking neurons (nengo.SpikingRectifiedLinear()). Once done with training (and in this example, saving weights… which you don’t necessarily need to unless looking for some flexibility), you can once again proceed with inference with proper test data arguments as follows:
converter = nengo_dl.Converter(
model,
swap_activations={tf.nn.relu: nengo.SpikingRectifiedLinear()},
)
net = converter.net
nengo_input = converter.inputs[input]
nengo_output = converter.outputs[dense1]
with nengo_dl.Simulator(net) as sim:
sim.load_params("mnist_params")
data = sim.predict({nengo_input: test_images[:n_test]})
BTW, model.fit(...) can also work with data generators. All the above code snippets are from the articles I have linked to give you the exact context of the next steps, and you might need to code up some extra for data handling. Also note that both the articles use Functional API of TF to create a model and not the Sequential API which you have used. I don’t think this should cause any issue, but in case it does, switch to Functional API and let us know if you still face problems in model conversion or execution.
Hi this explanation was great! I am still having a lot of trouble formatting the dataset in a way in which the nengo_dl model will accept it. Here’s the dataset which I am referring to: Grasp-and-Lift EEG Detection | Kaggle
As a result, I am unable to format the inputs correctly. Here’s a list of the shapes of each layer and inputs:
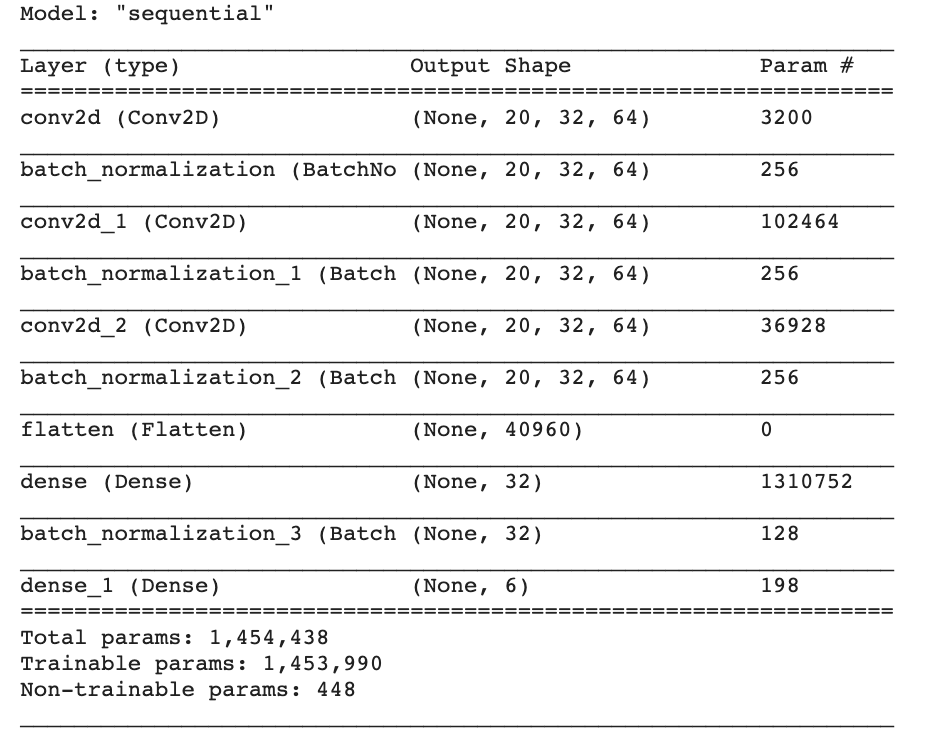
Any help would be appreciated please. Thanks!
Hello @CodeHelp1, with respect to your model summary above, I don’t see the InputLayer which denotes the input shape to your model. Your above model is sequential, and I cannot vouch if sequential models can be successfully converted. I have experimented with functional models and they can be converted successfully. Here’s more details if you don’t know creating functional api models. In fact, both the above linked tutorials create functional API based models. The reason I am not so sure of sequential models is that… as you can see in your model.summary() output, you don’t have any reference for InputLayer info (i.e. input shape etc.) and if Nengo-DL converter requires the InputLayer info to structure the input data internally, then it simply wouldn’t find it in sequential api based model you passed to the nengo_dl.Converter(). Hence, my suggestion is to first get a working model with functional api and then see if sequential api based model works with the nengo_dl.Converter() (if it works, please do let me know too!).
Next, with respect to data formatting for your project, you would be the best person to know how the input data to your model should be structured. We can definitely help you with core concepts about the data formatting for Nengo-DL model which should be generalizable. Below is one of the methods in which you can prepare your data for a Nengo-DL model.
As you know, we first train our TF model as it is before seeking conversion of it to the spiking one. So while training your TF model, you can proceed with training data creation as you do normally. E.g. In the tutorial, you will find that when you create a 2D-CNN model (which I can see is yours as well) and get its summary, following will be the output.
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
average_pooling2d (AveragePo (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 16, 64) 18496
_________________________________________________________________
average_pooling2d_1 (Average (None, 8, 8, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 128) 73856
_________________________________________________________________
average_pooling2d_2 (Average (None, 4, 4, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 2048) 0
_________________________________________________________________
dense (Dense) (None, 512) 1049088
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 1,147,466
Trainable params: 1,147,466
Non-trainable params: 0
_________________________________________________________________
and in the first layer: InputLayer you will see that the model requires matrices of shape (None, 32, 32, 3) where None is actually the batch size. So effectively, each of your training data sample should be of shape (32, 32, 3) and training labels should of appropriate shape as per your loss function. Up till this step, there is no special structuring of data for Nengo-DL spiking model. For reference of creating batch wise TF compatible data, I am posting a sample code (again from the linked tutorial):
# Create the data generator for training and testing the TF network.
def get_data_generator(batch_size=128, is_train=True):
"""
Returns a data generator.
Args:
batch_size <int>: Batch size of the data.
is_train <bool>: Return a generator of training data if True
else of test data.
"""
if is_train:
for i in range(0, x_train.shape[0], batch_size):
yield (x_train[i:i+batch_size], y_train[i:i+batch_size])
else:
for i in range(0, x_test.shape[0], batch_size):
yield (x_test[i:i+batch_size], y_test[i:i+batch_size])
where
# Load the CIFAR-10 dataset.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
and you can check for the before and after shapes of the training/test data. Note that the author is creating batches of test data here in function get_data_generator() so as to also test the model in TF mode.
Once you have trained your TF model, as I described in this comment, you can convert it to the spiking model to run it in testing mode. Now comes the special structuring of test data. First step, you need to flatten your test data. Second step, you need to tile it for n_steps parameter, and that’s it. You don’t need to necessarily modify the test labels as you might be simply comparing it with the predicted labels. Here’s the code where the tutorial does it.
# Tile the test images.
def get_nengo_compatible_test_data_generator(batch_size=100, n_steps=30):
"""
Returns a test data generator of tiled (i.e. repeated) images.
Args:
batch_size <int>: Number of data elements in each batch.
n_steps <int>: Number of timesteps for which the test data has to
be repeated.
"""
num_images = x_test.shape[0]
# Flatten the images
reshaped_x_test = x_test.reshape((num_images, 1, -1))
# Tile/Repeat them for `n_steps` times.
tiled_x_test = np.tile(reshaped_x_test, (1, n_steps, 1))
for i in range(0, num_images, batch_size):
yield (tiled_x_test[i:i+batch_size], y_test[i:i+batch_size])
So if you haven’t gone through the linked tutorials yet, please go through them and try understanding/executing them on your system first, and feel free to raise any doubts pertaining to conversion or the training/test data structuring. One important thing you might want to do would be to output the training data/labels and test data/labels shape to see how they are fed to the TF/Nengo-DL models and try getting a correlation with your project’s data.
Thanks a lot! This makes more sense now. I just wanted to ask whether this conversion from the keras to nengo and then to a spiking neural network is complete? Because, it seems to use activation functions rather than like a LIF neuron model. How would I incorporate LIF rather than the spiking activation function please?
Hi @CodeHelp1,
The term “activation function” is a catch-all term for the function used to convert a neuron’s input current into a firing rate. Spiking neurons have a similar concept, and if you take a spiking (e.g., LIF) neuron, and do a sweep of the input currents, and then measure the steady-state output firing rate, you essentially reconstruct an activation function for that neuron.
In NengoDL, when you create the NengoDL converter with the swap_activations parameter, if you specify a spiking neuron model, internally, NengoDL will use the spiking neuron instead of the rate-based one. If you want to use the LIF neuron for example, you’ll want to do:
converter = nengo_dl.Converter(
model,
swap_activations={tf.nn.relu: nengo.LIF()},
)
I would caution however, that while making such a swap is straightforward, it might not work as intended. This is because the original network was trained with the ReLU neuron type, which has a different activation function as the LIF neuron – the consequence of which is that the weights trained for the ReLU neuron may not work as well for the LIF neuron.
In order to get around this, what you’ll want to do is to create a NengoDL converter network with the LIF neuron type (spiking or not), and then call sim.fit on the converted network to re-train the weights for the LIF neuron. Note: If you modify the original network to use LIF neurons (see the example link below), the first sim.fit call will use the LIF neuron type, so you won’t need to re-train it.
Alternatively, you can create your own LIF (rate) neuron type in Keras, and use that activation function for the Keras training step.
Here’s an example of how you would create an LIF-based Keras / NengoDL network to train: Optimizing a spiking neural network — NengoDL 3.6.1.dev0 docs
And here’s an example of how you would train a converted network using a different neuron activation function (see the train function): This page has moved
With the above statement, you are mixing a bit of concepts here. So this is how conversion goes… you first create a model with rate neurons (i.e. the neurons which directly output their activity and not the spikes). TF-Keras helps you in creating such a model and train it. Next, you replace the rate neurons with spiking neurons to get a trained spiking network. Nengo-DL helps you in doing so. I don’t think Nengo specifically has any role to play here as it implements NEF (Neural Engineering Framework) and in Nengo-DL you don’t use the Decoders etc. get the output of a spiking neuron (@xchoo and others to correct me if I am wrong here).
Next, as your trained model is now composed of spiking neurons, the conversion is complete. We don’t train models with spiking neurons because
Training algorithms for SNNs are also more difficult to design and analyze, because of the asynchronous
and discontinuous way of computing, which makes a direct application of successful backpropagation
techniques as used for DNNs difficult.
(source: section 1.3 first paragraph).
@xchoo , with respect to the following,
by re-train do you mean that the network is first trained in TF with rate neurons, and then you replace the rate neurons (e.g. ReLU) with LIF (spiking or rate version of it) and then fine tune the network weights again? If yes, then during re-training with spiking LIF, does Nengo-DL use spike-aware training behind the scenes (i.e. still back-propagate errors in context of rate LIF) or does Nengo-DL use a continuous and differentiable approximation of the LIF membrane potential equation during re-training as mentioned below?
In this paper, we introduce a novel technique, which treats the membrane potentials of spiking neurons as
differentiable signals, where discontinuities at spike times are considered as noise. This enables an error
backpropagation mechanism for deep SNNs that follows the same principles as in conventional deep
networks, but works directly on spike signals and membrane potentials.
Nengo does play a role here, but only if you use sim.run. Otherwise, NengoDL mostly uses TF for the training process. As a note, while Nengo does have NEF functionality built into it, it is still a general purpose neural simulator and is capable of simulating any neural network, NEF or not! ![]()
Yes. That’s correct. Although, the re-training is only needed if @CodeHelp1 just wants to append additional code to their original code. If they were to rewrite the original TF network to be LIF neuron aware, then no re-training is required.
Both Nengo and NengoDL use rate-based approximations for the weight training (or in the case of Nengo, to compute the encoders and decoders if they are being used).
Thank you @xchoo for confirming. Can you please elaborate a bit on above? What role does Nengo play while doing sim.run()? I am assuming that all the calculations pertaining to current calculation, membrane potential change, smoothing the spikes etc. are not considered as part of core Nengo in context of Nengo-DL.
When you convert a TF model to a NengoDL model using the NengoDL converter, the Keras objects are mapped onto their respective Nengo-native implementations. As an example, the tf.keras.layers.Dense object would be mapped onto a nengo.Ensemble object. When the sim.run call is made, the Nengo backend is used to run all of these Nengo objects as if they were a regular Nengo network.
I should note that NengoDL itself doesn’t have any neural simulation code. It either uses TF, or Nengo to train / run networks.
Got it @xchoo. Of course… the nengo.Ensemble is supposed to run using Nengo backend (with or without the NEF). Thanks!
Yeah makes a bit more sense. So if I want a spiking neural network instead of a deep neural network, I need to use the Nengo_dl converter and then retrain it?
Not necessarily. In the context of above discussions, you need to retrain your spiking network when you replace the ReLU neurons with LIF spiking neurons and that’s because the trained weights do not adapt well to the LIF neurons, rather they do just as fine with SpikingRectifiedLinear() (which is a spiking version of ReLU) neurons.
In short, if you replace ReLU with SpikingRectifiedLinear() while conversion, no need to retrain your converted network.
I just want to clarify some terminology - A deep neural network is considered “deep” typically only because there are many layers to it (i.e., “deep” is a description of the network’s topology). A spiking neural network, however, is just a network that utilizes spiking neurons, and does not apply constraints to the network topology at all. Rather “spiking” describes the spiking nature of the activation function used for each neuron.
And as @zerone pointed out, if you just want a spiking version of your deep neural network, then creating a NengoDL converter with
swap_activations={tf.nn.relu: nengo.SpikingRectifiedLinear()}
would suffice. In that instance, your network would be using a spiking rectified linear neuron.
Hi thanks a lot for all your responses. Sorry I’m quite new to Spiking Neural Networks, I had another question. My CSV file to be totally clear is actually a list of EEG signals. How do I generate compatible data with the CSV please - do I use the same technique as the image? Here’s the dataset for reference: [Grasp-and-Lift EEG Detection | Kaggle]. Thank you!
Hello @CodeHelp1, organizing your data of course depends upon what you want to do with it. We don’t know your plans with the data, can you throw some light to it? Like… do you want to classify it, or run a regression model on it? Once you answer this, you should think about what kind of Neural Network (NN) model would you use for your purpose?
For images, it’s mostly about classifying them and they have a spatial structure, does your EEG data have 2D/3D spatial structure? And should you limit yourself to just using NN models? why not some other spiking cognitive models? As you can see… answer to all these questions very much depends on what you want to do with your EEG data.
From the link you mentioned, it seems that the EEG data is a time series data and you need to classify it in six classes (assuming from the data description). I haven’t downloaded the data, but it seems that each data sample will be a 1D vector, and each vector will probably have no 2D spatial structure (I may be wrong here, as I haven’t investigated the data). For time series classification you can use LSTMs etc. (which does not have Nengo-DL layer equivalent) or use LMUs! an awesome spiking equivalent to LSTM. Let us know accordingly!
Hi yes I am classifying them. Currently, I am using a simple CNN LeNet Model and I also have an LSTM model.
Good to know that you intend to classify them. However, CNN and LSTM architectures are entirely different and (in general) used for different purposes as I mentioned earlier. Although you can use CNNs on Time-Series data as well as LSTMs on visual data (after flattening the image matrices). So in case you finalize on CNNs, refer the articles on MNIST and CIFAR that has been linked in this thread. And if for some reason you decide upon LSTMs (which does not have spiking layer equivalent as Conv/Dense layers have in Nengo-DL), you will have to understand how LMUs work and refer the related articles (linked in my previous reply) for developing a spiking model (unfortunately I am not well versed with LMUs).