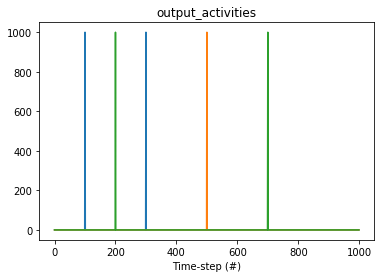
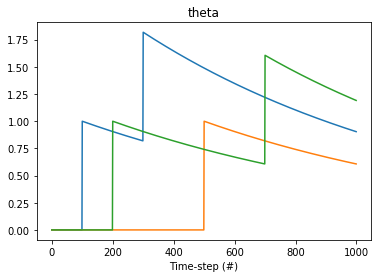
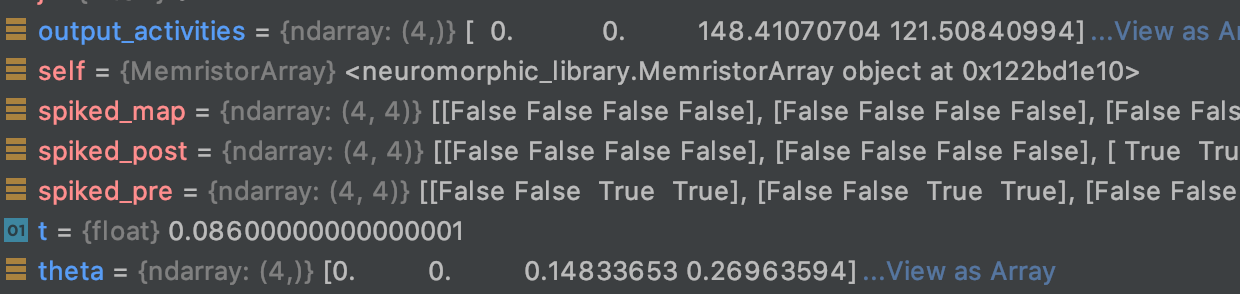
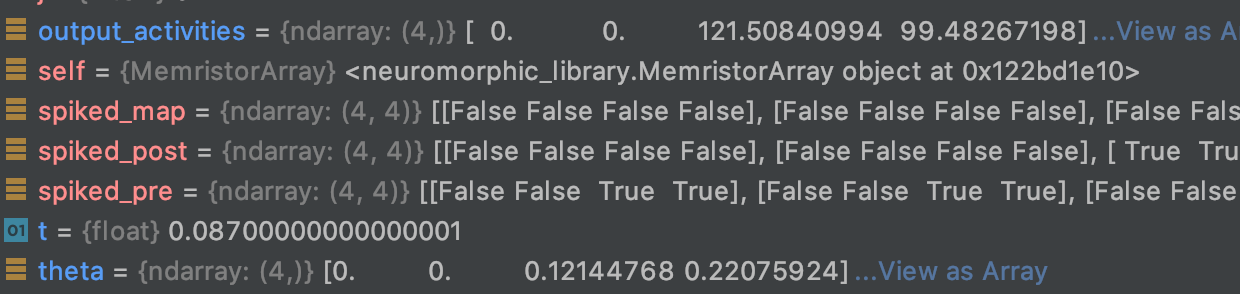
I was imagining that the returned vector would be the average of post-synaptic activation for each neuron over one second, but what I see is the following:
i.e., that the first non-zero component of theta is always a scaled version of the first non-zero component of output_activities, while I’m not clear of what the following components of theta represent.
Does theta represent the \Theta_m in the BCM rule ? Or should I be using some other method to check if to potentiate or depress the synapse afferent to each postsynaptic neuron?
In your code you have self.theta_filter which I assume should be just theta_filter. Given this code, theta represents the filtered output over time of output_activities which is being interpreted as a time-series. To give a concrete example:
import matplotlib.pyplot as plt
import nengo
# 3 neurons over 1000 time-steps
output_activities = np.zeros((1000, 3))
# put spike at steps 100 and 300 for neuron 0
output_activities[[100, 300], 0] = 1000
# put a spike at step 500 for neuron 1
output_activities[500, 1] = 1000
# put spikes at steps 200 and 700 for neuron 2
output_activities[[200, 700], 2] = 1000
theta_filter = nengo.Lowpass(tau=1.0)
theta = theta_filter.filt(output_activities)
plt.figure()
plt.title("output_activities")
plt.plot(output_activities)
plt.xlabel("Time-step (#)")
plt.show()
plt.figure()
plt.title("theta")
plt.plot(theta)
plt.xlabel("Time-step (#)")
plt.show()
Although it is also possible to simulate the synapse one step at a time in your code using the make_step method on the synapse, that’s usually not what you want to be doing. If you are modifying the BCM rule and need to supply filtered activities as terms in the rule, that is usually done either by applying a synapse to the nengo.Connection that is calculating the corresponding term. Or, by building a synapse into the signal that is being used by the learning rule operator. I suspect that what you are trying to do is closer to the latter.
Thanks for your great reply.
I’m actually trying to reproduce something similar to the BCM rule inside a Node() object.
Say that I have 4 post synaptic neurons like in the example screenshots I posted, how should I go about checking when to potentiate or inhibit their synapses?
My code would go something like this:
def mBCM( self, t, x ):
input_activities = x[ :self.input_size ]
output_activities = x[ self.input_size: ]
theta_filter = nengo.Lowpass( tau=1.0 )
theta = theta_filter.filt( output_activities ) / self.dt
# function \phi( a, \theta ) that is the moving threshold
update_direction = np.sign( output_activities - theta )
# squash spikes to False (0) or True (100/1000 ...) or everything is always adjusted
spiked_pre = np.tile(
np.array( np.rint( input_activities ), dtype=bool ), (self.output_size, 1)
)
spiked_post = np.tile(
np.expand_dims( np.array( np.rint( output_activities ), dtype=bool ), axis=1 ), (1, self.input_size)
)
spiked_map = np.logical_and( spiked_pre, spiked_post )
# we only need to update the weights for the neurons that spiked so we filter
if spiked_map.any():
for j, i in np.transpose( np.where( spiked_map ) ):
self.weights[ j, i ] = self.memristors[ j, i ].pulse( update_direction[ j ],
value="conductance",
method="same"
)
so, basically, I’m calculating the \Phi term in BCM by using post-synaptic neurons j to decide if to raise or lower the weights for neurons i afferent to j iff. both i and j have spiked in this timestep.
Is using update_direction[j] the correct way to check if the weights to neuron j need to be raised or lowered?
Is it correct to scale theta by the simulation timestep self.dt in order to make it comparable to the postsynaptic firing rate output_activities?
How would I interpret this finding of mine “that the first non-zero component of theta is always a scaled version of the first non-zero component of output_activities , while I’m not clear of what the following components of theta represent” ?
I can’t say for sure without looking back into the details of BCM, but it looks like the right idea.
I’d first recommend making sure that you fully understand the example from my previous post. It seems as though you are expecting the call to filt to be filtering one time-step per call. However, as shown in my example, it treats the entire input as a time-series and applies the filter across an axis. The filter does not maintain state between consecutive calls when used in this way. It does if you use the make_step method to create a stateful step function – but I believe this would be overkill for what you want.
It looks like what you are trying to do is have theta be a filtered version of output_activities?
If so, when setting a synapse on the connection, Nengo will apply it statefully to filter the corresponding signal over time. Therefore, what you can do is increase the dimension of x by an additional (output_size = len(output_activities)), and then connect into your node like so:
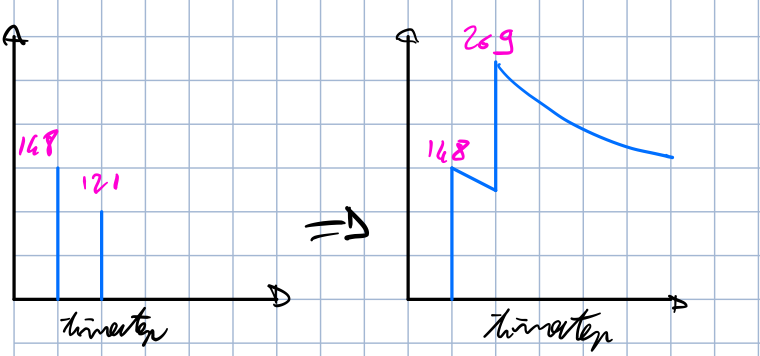
For anyone else confused by this, basically the output_activities vector of synaptic activities was interpreted by .filt() as a time series of activity of a single neuron, instead of the activities of a population of neurons at a given timestep.
This is why output_activities= gave theta=; they were seen as two spikes in two successive timesteps of a single neuron: 148+121=269 of activation at the successive timestep!

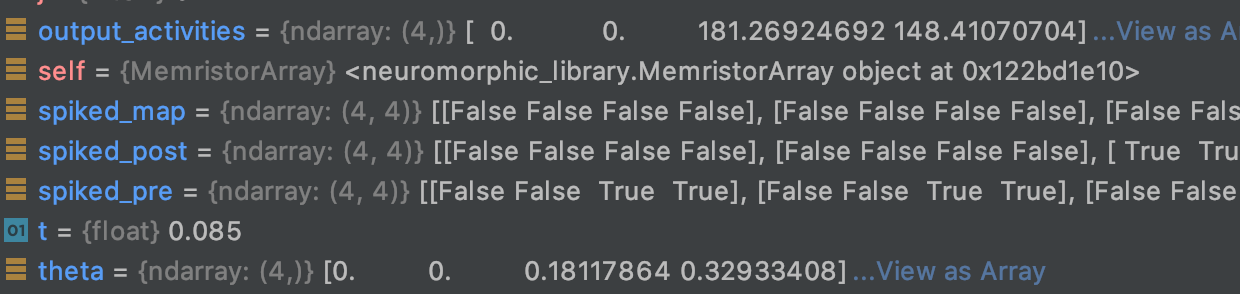
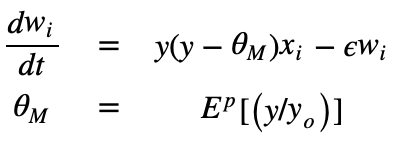 ? Or should I be using some other method to check if to potentiate or depress the synapse afferent to each postsynaptic neuron?
? Or should I be using some other method to check if to potentiate or depress the synapse afferent to each postsynaptic neuron?