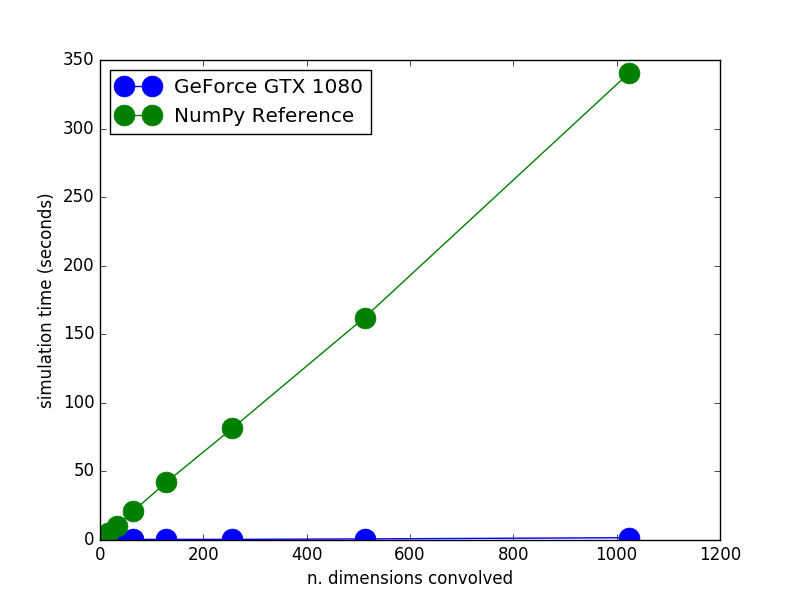
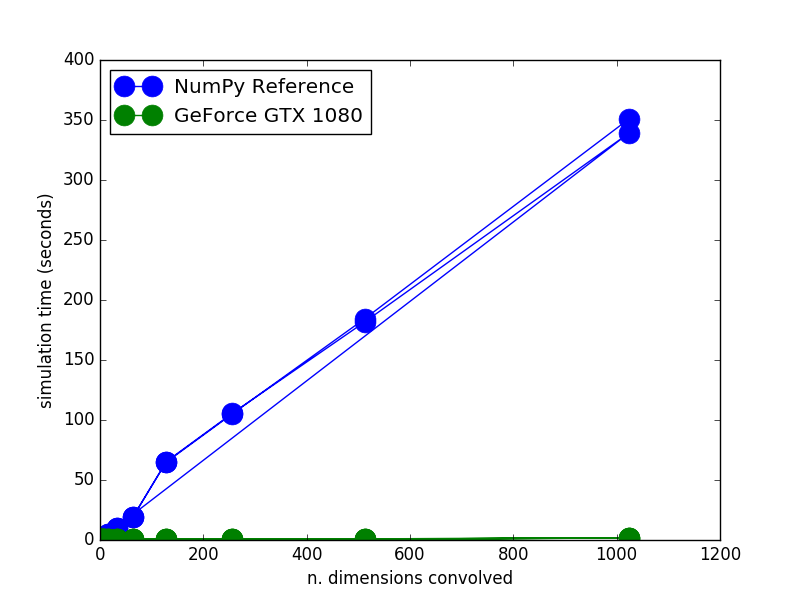
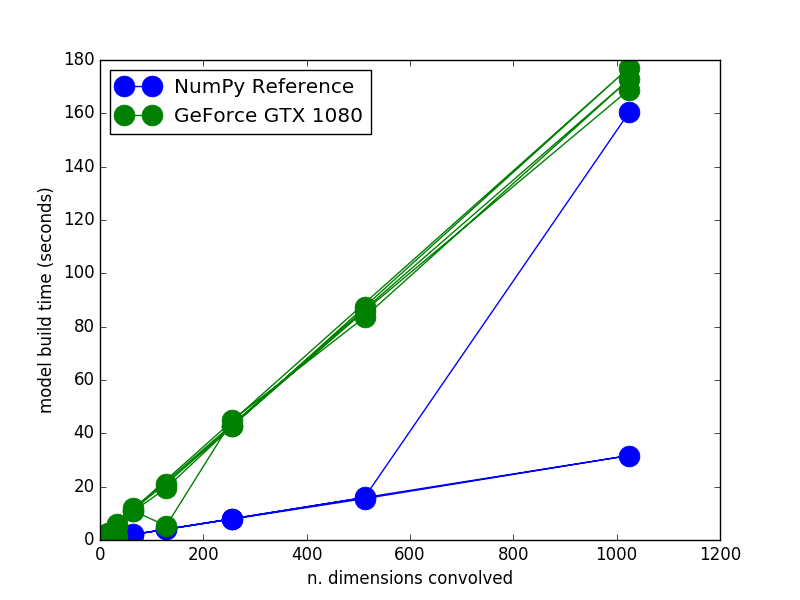
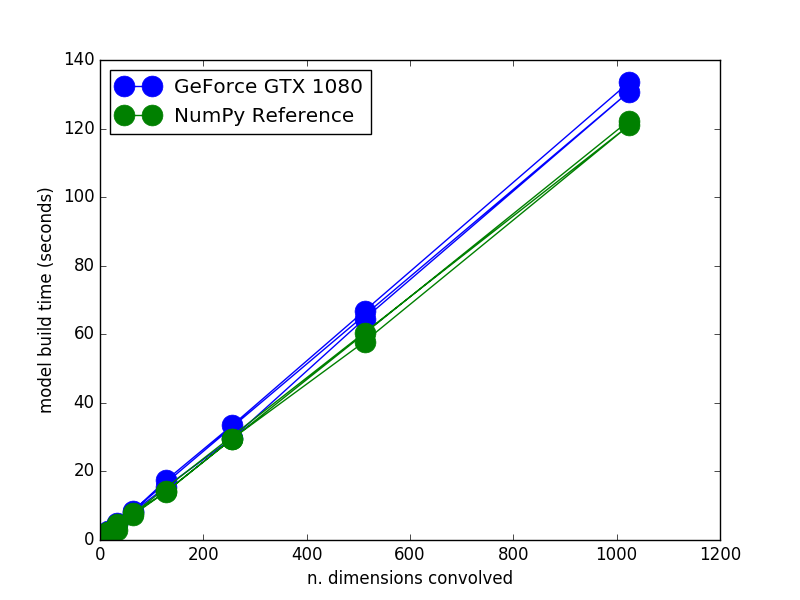
Excitingly, we (my lab) recently set up a new PC just for Nengo simulation.
Hardware setup
CPU: Intel® Core™ i7-6700K CPU @ 4.00GHz × 8
MB: Gigabyte Z170X-Gaming 5
RAM: King-stone 16GB*2, 32GB available
Swap: 32GB
GPU: NVIDIA GeForce GTX 1080 8GB
Storage: INTEL SSDSC2KW24 240GB
OS: Ubuntu 16.04 LTS 64-bit
GPU driver
NVIDIA binary driver - version 367.57 from nvidia-367
CUDA toolkit
nvcc --version
nvcc: NVIDIA ® Cuda compiler driver
Copyright © 2005-2016 NVIDIA Corporation
Built on Sun_Sep__4_22:14:01_CDT_2016
Cuda compilation tools, release 8.0, V8.0.44
Package versions
python 3.5
nengo==2.2.0
numpy==1.11.2
pyopencl==2016.2
nengo-ocl==1.0.0
I had run some examples for CUDA toolkit and pyopencl, I think they worked.
As to nengo-ocl, I’ve try to run the example files found here: https://github.com/nengo/nengo_ocl/tree/master/examples
But without instruction, I actually don’t know how to make it put out some useful information. So I’m here to ask for your advice!
Originally I thought this is an easy job, but it took me entire two days of work and reinstalling entire Ubuntu three times to get to current state.
(Yeah I’m relatively new to Linux and all these tools.)
Someday I will list out the steps I took to set up the stable system, after I test nengo-ocl really works.