I’d like to implement a system using natural language processing. Specifically, I want to create a system that can input sentences and output appropriate answers when entering simple questions.
I am interested in the framework of Holographic reduced representations, that is to something like word vectors.
I am a student, and I am beginner about studying on the system using Nengo. So, I don’t have much knowledge. I’d appreciate if you answer questions.
As I mentioned earlier, I would like to build a system that can handle natural language processing. Therefore, I need to construct word vectors to express sentences as holographic representations.
When I tried to make this system, I faced problems.
How can we parse sentences? Is there a learned system in the field of deep learning? If so, what is it?
Originally, I’m trying to create word vectors with SP, but is it needed? In the field of deep learning, there are famous word vectors such as “word2vec”. I don’t know well about them, but is there something that like they cannot but SP could do.
Similar to question 1. In a holographic reduced representations(HRRs) paper, since only a small number of simple example sentences are shown, it is not hard to express sentences as HRRs. However, in practically, a large number of sentences are entered. So I think that automation for making them is necessary.
This is that I have made easily, but I think I cannot create all sentences manually.
So, are there clear ways to create word vectors using SP or learned libraries?
Or is it a research theme that has not been done yet to learn word vectors using SP?
In addition to the above questions, if you have any advice on research, please let me know.
Any kind of information will be useful information for me, so I’d like to have answers and advice by all means.
Hi @green_clover, I can add a few comments to help further answer your questions.
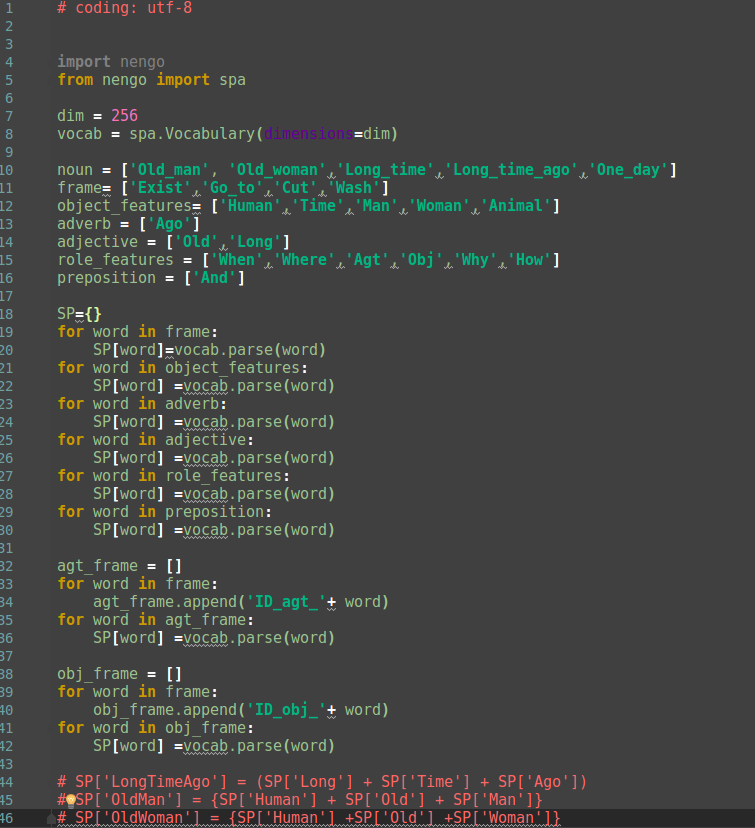
Regarding (1), if you want to build structured sentence representations, one thing you can try is defining strings that represent collections of role-filler pairs. For example, OLD_MAN*NOUN + WALKS*VERB might correspond to the sentence “The old man walks.” One advantage of this approach is that you can call vocab.parse() on such strings to return a semantic pointer object that is structured in accordance with the convolution and addition operators they contain. (i.e., the semantic pointer returned for the above example string would be built by convolving and adding other semantic pointer objects such those corresponding to OLD_MAN, NOUN, etc.).
Regarding (2), when you use a spa.Vocabulary to create semantic pointers (e.g., via vocab.parse(word)), you are taking random vectors from the D-dimensional unit sphere (where D in your code is 256) that satisfy a minimum similarity constraint - all of the semantic pointers in the resulting vocabulary are approximately orthogonal. If you want to use pretrained vectors, you can do something like the following:
for word in words:
vocab.add(word.upper(), word2vec[word])
where vocab is a spa.Vocabulary object, word is a string, words is a list of strings (e.g., the list of nouns you have defined), and word2vec is a dictionary that maps from strings to numpy arrays. What this will do is initialize the semantic pointers in your vocabulary using pre-existing collection of word vectors. You can use a tool like GenSim to load Google’s word2vec demo file and create the needed dictionary. One thing to check for is whether the words you want to model are all present in the preexisting collection of word2vec examples. Another thing to consider is that word2vec embeddings do not necessarily exhibit the properties needed to support effective binding via convolution.
Regarding (3), I think the challenge here is to find some way of automatically converting real-world sentences into strings that describe collections of role filler pairs that you can call vocab.parse on. One way you might try to do this is by using an NLP library to get part-of-speech (POS) tags for each word in a sentence, and then automatically generating a new string of the form Word_1 * POS_1 + Word_2 * POS_2... which you can then use in your SPA model. A more complicated version of this approach might involve using parse tree information in some way, since POS tags do not really capture anything about the sentence’s structure.
Anyway, this is all very much an open area of research, so please let us know if you have any follow up questions!
Thank you for your answer, pblouw! I understand how you interpret what I am wondering!
I have additional questions. Now, I have two example sentences:
OLD_MAN*NOUN + WALKS*VERB (Old man walks.)
OLD_WOMAN*NOUN + WALKS*VERB (Old woman walks.)
Then, should OLD_MAN have some similarity with OLD_WOMAN? In fact, both “OLD_MAN” and “OLD_WOMAN” have features of “old” and “human”, so I think it is incorrect that semantic pointers of “OLD_MAN” and “OLD_WOMAN” are created by
vocab.parse(“OLD_MAN”)
vocab.parse(“OLD_WOMAN”)
I think it is correct that semantic pointers of “OLD_MAN” and “OLD_WOMAN” are created by using vocab.add( ) and word2vec.
Semantic pointers of words are created by using the former method, sentences(additions of roll-filler pairs) are input, and I observe if my model exactly answer simple question. Is there any meaning? I think no.
I have another questions. I don’t use word2vec, but I use a dictionary similar to word2vec. Vector dimensions in it is 300. In addition, mean and variance of vector elements in it is not 0 and 1/n respectively (n is 300). To make mean and variance is 0 and 1/n, I modify these vectors by normalizing them. Is this number of dimensions enough for natural language processing?
Or, should I expand the vector dimension while keeping similarity? If you think so, how should I do…? I have no idea…
Great - I’m glad to have helped a bit! With regard to your additional questions, you are right that if you call vocab.parse on the strings OLD_MAN and OLD_WOMAN, they will be assigned random unit vectors that are approximately orthogonal and hence highly dissimilar. So, if you want to account for the fact that these concepts both share the features OLD and HUMAN, you’ll have to either build these features in explicitly (e.g., you could define each semantic pointer as a collection of features, something along the lines of OLD_MAN = AGE * OLD + KIND * HUMAN + ....), or use pretrained vectors as you suggest.
Regarding vector dimensionality, 300 dimensions should be more than in enough - typically, the word embeddings used in NLP applications are somewhere in the range of 50 - 500 dimensions. And the general heuristic for choosing the dimensionality is often performance on some task of interest (e.g. predicting synonyms), or the size of the vocabulary you wish to handle. One further point is that normalizing your vectors to unit length does not necessarily guarantee that their elements will be distributed with a particular mean and variance. To see whether your vectors support binding and retrieval, I would suggest doing some simple tests to see whether you can build and manipulate a few basic structures and then re-evaluate your approach if necessary.