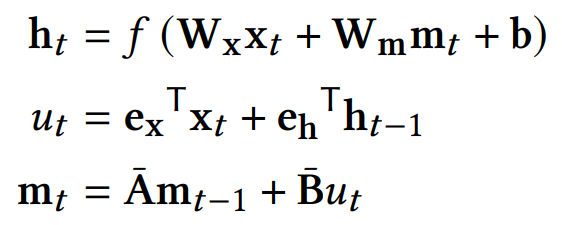I have read the paper titled “Hardware Aware Training for Efficient Keyword Spotting on
General Purpose and Specialized Hardware” . In this paper, the LMU was modified as below:
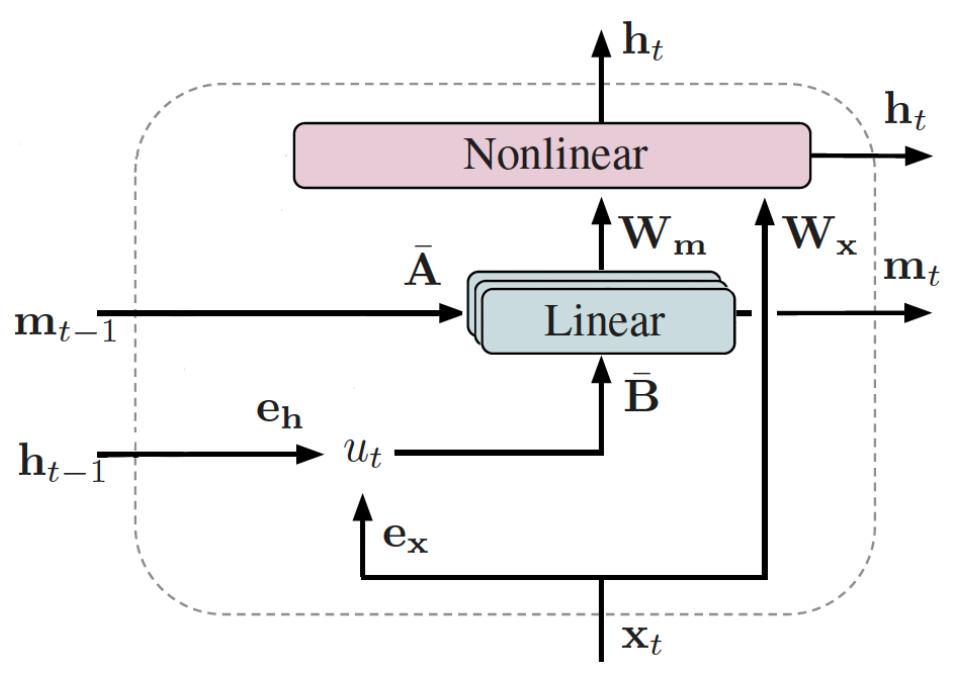
"we have removed the connection from the nonlinear to the linear layer, the connection from the linear layer to the intermediate input 𝑢𝑡, and the recurrent connection from the nonlinear layer to itself. As well, we have included multiple linear memory layers in the architecture; the outputs of each of these layers are concatenated before being mapped to the nonlinear layer via the matrix 𝑊𝑚.
"
I read the some origin codes of LMU that as below:
state for the hidden cell
h = states[:-1]
# state for the LMU memory
m = states[-1]
# compute memory input
u_in = tf.concat((inputs, h[0]), axis=1) if self.hidden_to_memory else inputs
if self.dropout > 0:
u_in *= self.get_dropout_mask_for_cell(u_in, training)
u = tf.matmul(u_in, self.kernel)
if self.memory_to_memory:
if self.recurrent_dropout > 0:
# note: we don't apply dropout to the memory input, only
# the recurrent kernel
rec_m = m * self.get_recurrent_dropout_mask_for_cell(m, training)
else:
rec_m = m
u += tf.matmul(rec_m, self.recurrent_kernel)
# separate memory/order dimensions
m = tf.reshape(m, (-1, self.memory_d, self.order))
u = tf.expand_dims(u, -1)
# update memory
m = tf.matmul(m, self.A) + tf.matmul(u, self.B)
# re-combine memory/order dimensions
m = tf.reshape(m, (-1, self.memory_d * self.order))
# apply hidden cell
h_in = tf.concat((m, inputs), axis=1) if self.input_to_hidden else m
if self.hidden_cell is None:
o = h_in
h = []
elif hasattr(self.hidden_cell, "state_size"):
o, h = self.hidden_cell(h_in, h, training=training)
#print('removed h to h')
else:
o = self.hidden_cell(h_in, training=training)
h = [o]
return o, h + [m]
Could anyone who can show me how to modify the codes above to achieve the required LMU architecture?
Hi @Ryan. Fortunately no modifications are needed. The memory_d parameter is the number of memory layers. You can set this to be any positive integer when you create any LMU cell or layer. The additional connections are toggled via hidden_to_memory, memory_to_memory, and input_to_hidden, which all default to False.
You’ll want hidden_to_memory = True in order to get the h_{t-1} -> u_t connection that you see in the architecture diagram. You’ll also want input_to_hidden = True in order to get the x_t -> Nonlinear connection in the architecture.
Also note that the LMU allows passing in an arbitrary hidden_cell, and so you can make this a dense layer or similar to avoid the connection from hidden to hidden.
I took another look at the paper and this part of the description:
we have removed the connection from the nonlinear to the linear layer
is actually incorrect, as we have hidden_to_memory = True. The equations from the paper (below) and the architecture diagram are correct. Thanks for bringing this to our attention.
" Also note that the LMU allows passing in an arbitrary hidden_cell , and so you can make this a dense layer or similar to avoid the connection from hidden to hidden."
Do you mean that I create an extra dense layer? The input of this dense layer is LMU layer hidden cell h(t), and the output of this dense layer connects LMU layer h(t-1). I use this dense layer to avoid the connections from hidden to hidden?
The hidden_cell is the nonlinear f part that produces the h_t in the equation above, labelled “Nonlinear” in the architecture diagram.
If you use a Dense layer with a bias and activation function $f$ for the hidden_cell, and input_to_hidden = True, then you will get exactly $\mathbf{h}_t = f(\mathbf{W}_x \mathbf{x}_t + \mathbf{W}_m \mathbf{m}_t + \mathbf{b})$.
If you want $h_{t-1}$ to be an input to $f$ as well then that calls for a different hidden_cell, such as an RNN cell.