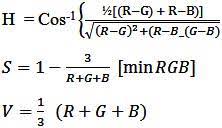Is there any intuition for choosing between a multi-D Ensemble vs. multiple 1-D Ensembles? EnsembleArray provides a very nice encapsulation of the latter, so the in/out Connection interface between the two options is similar.
representation efficiency: accuracy vs. number of neurons
CPU performance: build time (w/ and w/o caching) and run time
compatibility with various backends, including the neuromorphic hardware
Example NEF applications:
representing RGB values over a high-D feature, like a color image
ImageNet images would be 3x482x418 = 604k variables
representing a vector field over a volume (i.e. 3 scalar functions defined over a grid)
A volume with 40 grid points per dimension would be 3x40x40x40 = 192k variables
The key difference there is that RGB is just a representation that likely feeds forward into another layer, whereas a vector field could use recurrent connectivity to, for example, calculate a divergence function.
The main situation where you want to use multi-D ensembles over multiple 1-D ensembles is when you want to calculate a function that is (non-linearly) dependent on more than 1 variable. To do this your ensemble needs to have representations of all the relevant variables. If this isn’t a concern then you can probably build a smaller network using multiple 1-D ensembles.
representation efficiency will generally be higher with ensemble arrays
the build time should also be less with ensemble arrays (because you’re generally using less neurons)
ensemble arrays should work on all backends, as they’re just a short-hand for a bunch of ensembles as connections, so you shouldn’t have to worry about that.
So for the applications that you’ve listed, where the RGB is just storing a representation it sounds like an EA of 1D ensembles is the way to go.
After a quick look at wikipedia it seems like to calculate the divergence function of a vector field will require access to at least a few of the vectors at once, so you’ll need multi-D ensembles. It’s worth noting that EAs can be arrays of multi-D ensembles, so you still might want this set up. If you found that you could calculate this function with 12 represented dimensions, then you could make an ensemble array of 12D ensembles and this would do better on all of the metrics listed above than a single 192k-dimension ensemble.
The big difference is what class of functions you can compute out of the population. If you have separate Ensembles representing x and y, then you can only compute functions of the form f(x)+g(y). If you want to compute f(x,y) then you will need a combined Ensemble.
Note: this is a variant of the classic XOR problem in neural networks.
Also, I have a lot of fun optimizing networks by taking functions of the form f(x,y) and splitting them up so that they can be written as f(a)+g(b). My favorite example is computing the scalar product f(x,y)=xy. Instead of using a single 2D ensemble to do this, you can actually split that into two 1D ensembles. Here’s the trick:
To complicate things further, I’ll also note that if you manually set the encoders in a single 2D ensemble, then you can make it exactly like two separate 1D ensembles, so to a certain degree this is all just about picking the right encoders.
If I’m understanding correctly, multiple ensembles are always preferable unless they are not possible, which occurs when you need to calculate something not linearly separable. The XOR comparison makes sense to me. Just to check, are these statements right:
If you have a complex number $z=x+iy$ with one Ensemble for $x$ and one for $y$. You can represent $z^*z = x^2 + y^2$, but you cannot represent $||z|| = \sqrt{z^*z}$. Although, you could put an additional 1D Ensemble to do the square-root.
Calculating intensity value of RGB is a sum, so, if you only need that, keep them 1D. Calculating hue of RGB is a trig function of a fraction, so you would definitely make it 3D
I am still learning the nuances of encoders. That notebook is great. How problem-specific is that diagonal encoder approach? We once did something similar to try to minimize the number of neurons on Lorenz (it was 24), but that was largely trial and error. Of course, we picked Lorenz that time partly in order to avoid calculating inaccuracy https://github.com/lightwave-lab/Neuromorphic_Silicon_Photonics/blob/master/Neuromorphic_Silicon_Photonics.ipynb
If you have a complex number z=x+iyz=x+iy with one Ensemble for xx and one for yy. You can represent z∗z=x2+y2z∗z=x2+y2, but you cannot represent ||z||=z∗z−−−√||z||=z∗z. Although, you could put an additional 1D Ensemble to do the square-root.
Yes, that’s exactly correct. (One tiny little terminology thing – we’d say that you can compute those values, rather than represent. We tend to use the term represent to mean the identity decoder only. But that’s really just a convention we’ve fallen into.)
Calculating intensity value of RGB is a sum, so, if you only need that, keep them 1D. Calculating hue of RGB is a trig function of a fraction, so you would definitely make it 3D
Yes, unless you can find some interesting rearrangement of that calculation that separates the terms out. I don’t see one right now, though.
How problem-specific is that diagonal encoder approach? We once did something similar to try to minimize the number of neurons on Lorenz (it was 24), but that was largely trial and error.
Nice! That’s a pretty nice Lorenz result, and very interesting approach to the optimization. That diagonal trick is mostly specific to the fact that we’re computing the product, and the product has that nice decomposition. (Note: that decomposition will be familiar to analog computation people: e.g. https://www.edn.com/easy-four-quadrant-multiplier-using-a-quad-op-amp/ ). If you run backprop across the system, you end up with the same result. Indeed, whenever I’ve needed to try to optimize anything about the encoders, I’ve always either a) had some analytic decomposition to help out, or b) used backprop to optimize it.