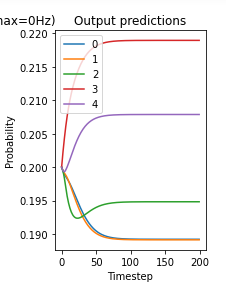
Hi,
I have a pretty simple 4 layer network with 3 input neurons, 2 hidden layers of 50 neurons each, and output layer of 5 neurons. All will RELU activation function.
All inputs and outputs are scaled to be between 0 to1 range.
The network is trained with SGD optimizer on 70000 samples using batch of 250
and MSE as a loss function.
15k samples for validation, and 15k samples for test
After several epochs the MSE loss of the network is under 0.02
Epoch 15/15
280/280 [==============================] - 1s 3ms/step - loss: 0.0200 - probe_loss: 0.0200 - val_loss: 0.0198 - val_probe_loss: 0.0198
But when all I do is change the RectifiledLinear activation function to SpikingRectifiedLinear the prediction results in MSE of 0.29, which is the output of data when almost all predicted by spiking network values are 0.
Network is “not working”
Playing with scale_firing_rates parameter has almost no effect.
I am attaching a simplified version of my code to demonstrate what i am doing.
I would be grateful to know if i am doing something wrong.
I am using python version 3.6.8rc1 and NengoDL 3.3.0
Thank you in advance!
def ConstructNetworkNengo(inputTrain,outputTrain,inputValidation,outputValidation,inputTest,outputTest):
steps = 1
inputTrainNgo = np.tile(inputTrain[:, None, :], (1, steps, 1))
outputTrainNgo = np.tile(outputTrain[:, None, :], (1, steps, 1))
inputValidationNgo = np.tile(inputValidation[:, None, :], (1, steps, 1))
outputValidationNgo = np.tile(outputValidation[:, None, :], (1, steps, 1))
inputTestNgo = np.tile(inputTest[:, None, :], (1, steps, 1))
#Build Network
input = tf.keras.Input(shape=(3,))
l1 = tf.keras.layers.Dense(50,activation=tf.nn.relu)(input)
l2 = tf.keras.layers.Dense(50,activation=tf.nn.relu)(l1)
output = tf.keras.layers.Dense(5,activation=tf.nn.relu)(l2)
model = tf.keras.Model(inputs=input, outputs=output)
converter = nengo_dl.Converter(
model,
swap_activations={tf.nn.relu: nengo.RectifiedLinear()},
)
net = converter.net
nengo_input = converter.inputs[input]
nengo_output = converter.outputs[output]
# run training
with nengo_dl.Simulator(net, minibatch_size=250, seed=0) as sim:
sim.compile(
optimizer=tf.optimizers.SGD(),
loss={nengo_output: tf.losses.mse},
)
sim.fit(
inputTrainNgo, {nengo_output: outputTrainNgo},
validation_data=(inputValidationNgo, outputValidationNgo),
epochs=15,
)
sim.save_params("./nengo-model-relu-1")
with nengo_dl.Simulator(net, seed=0) as sim:
sim.load_params("./nengo-model-relu-1")
data = sim.predict({nengo_input: inputTestNgo})
mse = MSE(outputTest, data[nengo_output][:, -1]) #normalized comparison
print('MSE Nengo prediction using RectifiedLinear of {} samples: {}'.format(len(inputTest), mse))
#Convert to Spiking
converter2 = nengo_dl.Converter(
model,
swap_activations={tf.nn.relu: nengo.SpikingRectifiedLinear()},
#scale_firing_rates=10000,
)
net2 = converter2.net
nengo_input = converter2.inputs[input]
nengo_output = converter2.outputs[output]
with nengo_dl.Simulator(net2, seed=0) as sim2:
sim2.load_params("./nengo-model-relu-1")
data = sim2.predict({nengo_input: inputTestNgo})
mse = MSE(outputTest, data[nengo_output][:, -1]) #normalized comparison
print('MSE Nengo prediction using SpikingRectifiedLinear of {} samples: {}'.format(len(inputTest), mse))
return model