I study unbinding toward a lot of sentences with SPA.
In my model, inputs are sentences. I assign memories each sentences.(For example, if the number of sentences is 20, the number of sentences is 20.) Then, in the case questions come in, my model selects appropreate memory, in which the appropreate sentence is stored, and perform unbinding the selected memory.
under the condition
Input sentences are follows:
sentences = ['U40*H47+Y5*I9+Z3*(U16*I25+P46*A4+R40*B27)',
'W4*D17+S3*M50+O9*(S28*H41+Y27*H19+Y44*(R24*D23+S35*I33+S42*(R48*J11+W45*I11+U27*C40)))',
'S3*M50+S19*L9+N18*B35',
'R40*B27+O40*G20+W11*(T37*L34+Q8*A37+O7*(U38*I11+S27*I45+O14*(P35*E24+Y12*E47+T19*F37)))',
'X24*C29+N15*H42+Z9*(X43*M24+S47*D5+U37*(O25*G39+Z46*E24+R47*G27))',
'U2*K50+W38*K42+W49*(Q30*I12+U2*K50+Q8*A37)',
'Y31*L9+Z50*E26+P1*M46',
'Y28*F9+T31*C34+Y11*(Q14*K29+U2*K50+P24*F30)',
'N37*J4+N38*J40+P17*(W6*B9+S49*I8+S28*(Z37*J28+S5*D26+T37*(O7*H29+Q12*J19+Z36*H46)))',
'T19*G23+T18*A44+Y27*(R5*C17+W47*B14+U24*(T19*G23+Y5*I9+S44*B36))',
'Y28*F9+U16*I25+Z23*(Z16*A39+O14*D15+W27*H5)',
'Q24*D2+X31*E3+P37*(T19*G23+O40*L7+R24*(U40*H47+Z16*A39+Q8*A37))',
'R43*D43+U2*K50+N31*B49',
'N34*L19+R16*C24+T25*(T34*I17+W46*F46+N37*(O50*E42+P36*G32+Z11*B35))',
'N34*L19+O14*D15+Y40*(R16*C24+O14*H45+O7*H29)',
'Z50*E26+S5*D26+S34*D34',
'P35*E24+S43*L17+T17*(U40*H47+T6*B43+X35*(N11*C39+N34*L19+X17*(S37*H16+S19*L9+Y26*D18)))',
'O25*G39+T6*B43+Z18*(X17*E36+O14*H45+N21*(Z16*A39+O14*D15+W27*H5))',
'N31*B49+P46*A4+P26*(S8*C28+R28*G4+Y22*(O40*G20+P36*G32+N31*(S37*H16+S19*L9+Y26*D18)))',
'N15*H42+Z42*L28+O37*D31']
These are random strings and the number of sentences is 20.
I create SP of these sentences and run my code.
memory.py (11.8 KB)
In dimensions=800, the results are
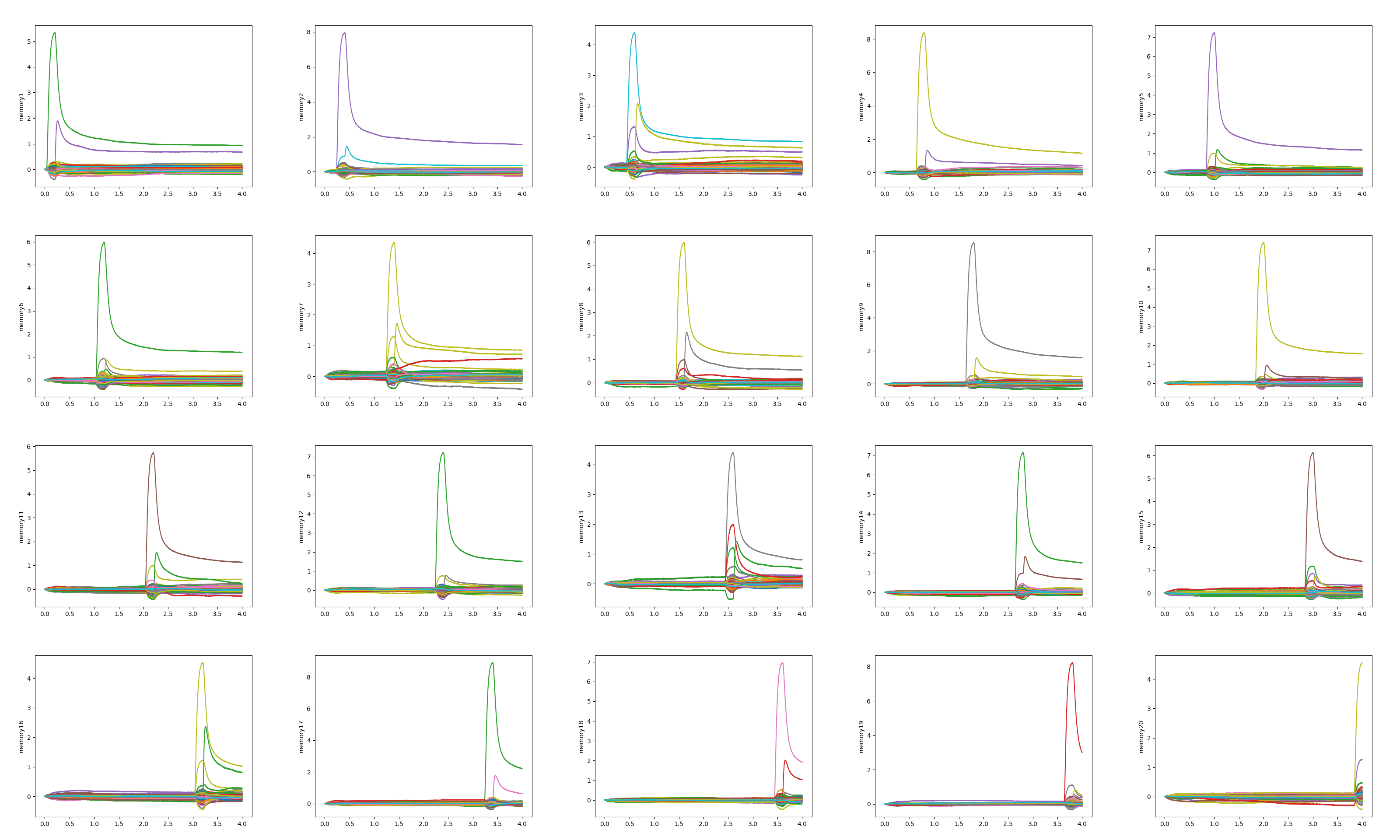
This is the good result for me because one memory stores one sentence.
In dimensions=1000, the results are
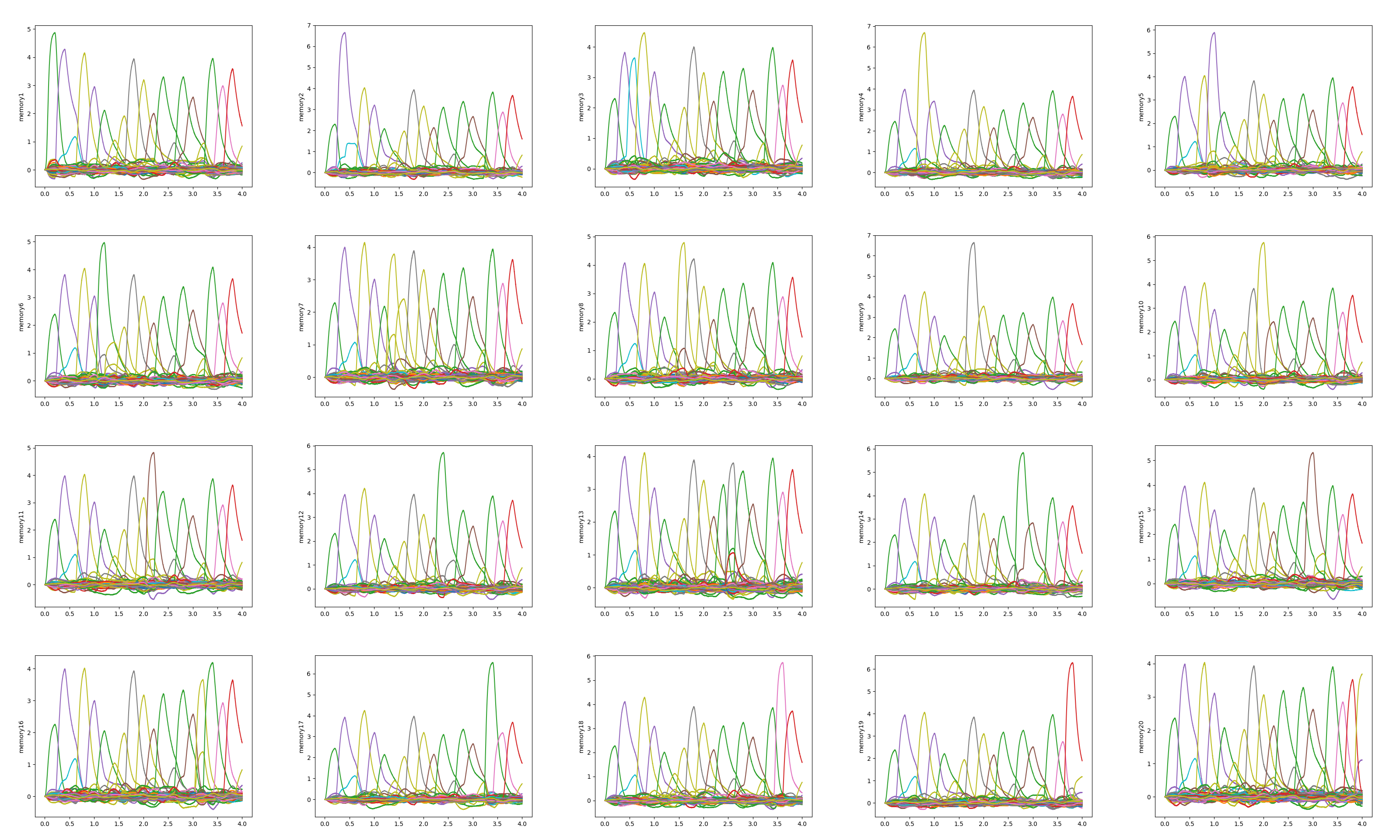
These result show me multiple sentences rather than one sentence in each memory.
This is not my desire.
The difference between them is dimensions, but my model seems to perform different behavior.
Why?
