For a recent publication we implemented Short-term Synaptic Plasticity (STSP) as proposed by Mongillo et al. in Nengo. The code and a short documentation can be found here.
Each neuron to which we want to apply the STSP learning rule will keep track of parameters Calcium (u) and Resources (x) which, after a neuron fires, will be increased and decreased respectively. Outgoing weights will be scaled relative to u and x. The parameters u and x relax back to baseline with time constants Tf and Td respectively, resulting in interesting behaviour; we get depression of weights on the time scale of Td and facilitation on the time scale of Tf as the figure below illustrates.
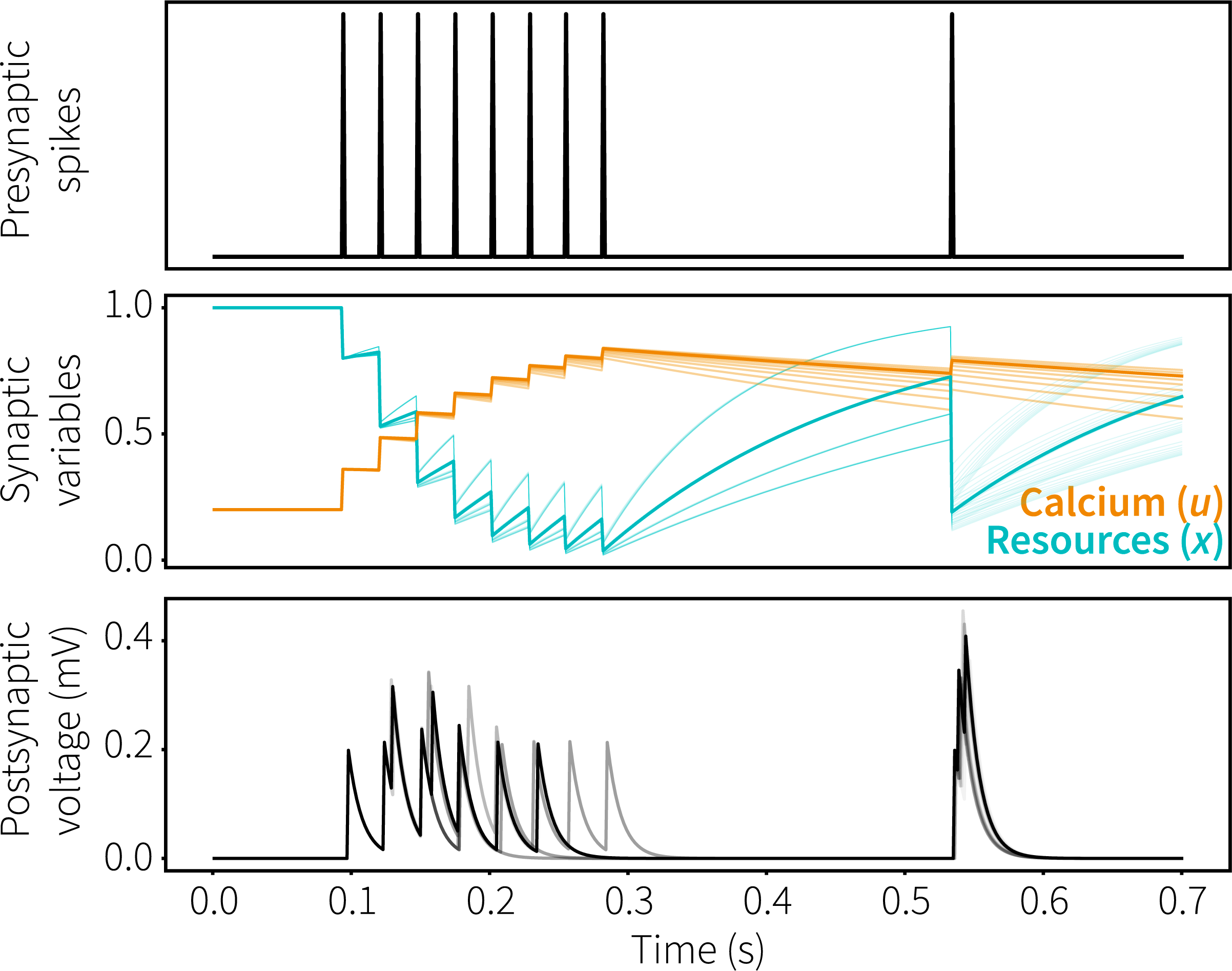
In our publication we showed how this system can be used effectively to maintain information in working memory without sustained firing (as is usually done in Nengo). Feel free to play around with the code, and if you have any questions I’d be happy to answer them!